

서 론
이 론
물리검층
자기조직화 지도(Self-Organizing Map, SOM)
SOM 앙상블(SOM 100)
결 과
입력 변수 선택(Feature Selection) 및 데이터 전처리
군집 분류 결과
결 론
서 론
물리검층은 시추공을 통해 지중의 다양한 물성을 측정하여 지하 환경의 정보와 특성을 파악하는 데 활용된다(Lai et al., 2024). 특히, 지중에 존재하는 다양한 암상을 효과적으로 식별하기 위해 물리검층 자료가 사용되며, 대표적으로 감마선 검층(Gamma Ray Log), 전기비저항 검층(Resistivity Log), 공극률 검층(Porosity Log)이 주요 기법으로 활용된다. 이러한 세 가지 검층 데이터를 통합하여 Triple Combo Log라고 하며, 이를 바탕으로 추가적인 물성 값을 다양한 관계식을 통해 도출할 수 있다(Holmes et al., 2019).
암상을 보다 정밀하게 식별하고 분류하기 위해 다양한 연구가 수행되어 왔으며, 특히 머신러닝 기법을 활용한 암상 분류 연구가 활발히 진행되고 있다. 기존 연구들은 주로 지도 학습 기반의 기법을 적용하였으며, 대표적인 연구 사례로 Salehi and Honarvar (2014), Merembayev et al. (2021), Kumar et al. (2022)가 있다. Salehi and Honarvar (2014)는 SVM (Support Vector Machine)을 이용하여 물리검층 자료를 기반으로 한 암상 분류 기법을 제안하였다. 또한, Merembayev et al. (2021)은 Random Forest 및 XGBoost를 적용하여 암상 분류 모델을 개발하였으며, Kumar et al. (2022) 연구는 MLP (Multilayer Perceptron)을 활용한 암상 분류 기법을 연구하였다. 지도 학습 기반의 기법들은 높은 예측 성능을 가지는 장점이 있지만, 학습을 위해 사전에 정답 데이터가 필요하므로 새로운 지역이나 데이터셋에 대한 확장성이 제한되는 한계점이 존재한다(Barbierato and Gatti, 2024).
반면, 비지도 학습 기반의 기법은 사전에 정답 데이터가 존재하지 않음에도 불구하고 숨은 패턴을 탐색하는 데 효과적이며, 지도 학습보다 다양한 데이터셋에 대한 확장성이 크다는 장점이 있다(Barbierato and Gatti, 2024). 이러한 특성을 바탕으로 비지도 학습을 활용한 암상 분류 연구 또한 활발히 진행되고 있다. Ali et al. (2023) 및 Hussain et al. (2022)는 물리검층 자료를 기반으로 비지도 학습을 적용한 연구를 수행하였으며, 특정 지역의 암상을 직접적으로 식별하기보다는 암상의 주요 물리적 특성을 분석하는 데 초점을 맞추었다. 그러나, 비지도 학습 모델의 특성상 정답 데이터가 존재하지 않기 때문에 기존 연구에서는 모델의 예측 정확성을 직접적으로 평가하는 것이 어려웠다.
본 연구에서는 비지도 학습 기반의 암상 분류 기법을 연구하여, 기존 기법들의 한계를 보완하고자 하였다. 이를 위해 자기조직화 지도(Self-Organizing Map, SOM)라는 비지도 학습 기반의 인공신경망 알고리즘을 사용하여 물리검층 자료를 바탕으로 암상을 분류하였다. 비지도 학습 환경을 최대한 모방하기 위해, 암상의 개수는 사전에 알고 있지만 개별 암상에 대한 구체적인 정보는 알지 못한다는 가정하에 모델을 학습시켰다. 이후, 사전에 제공된 암상 자료와 모델의 분류 결과를 비교하여 SOM 모델의 예측 정확도를 정량적으로 평가하였다. 이를 통해 지도 학습 기반의 기법이 가지는 데이터 의존성 문제를 극복하고, 다양한 환경에서 활용이 가능한 암상 분류 모델을 개발하는 것을 목표로 하였다.
이 론
물리검층
물리검층은 지층의 물리적 및 화학적 특성을 평가하기 위해 다양한 검층 기법을 조합하여 수행된다. 각 검층 자료는 특정 지질학적 특성을 반영하며, 이를 종합적으로 분석함으로써 보다 정밀한 지층 해석이 가능하다. 대표적으로 감마선 검층, 전기비저항 검층, 그리고 공극률 검층으로 구성된 ‘Triple Combo Log’가 널리 활용되며, 암상을 식별하고 유체의 존재 여부를 분석하는 데 핵심적인 역할을 한다.
감마선 검층 자료는 지중의 여러 암상에 포함된 방사성원소에서 방출되는 자연 감마선의 세기를 측정하는 검층 자료이며, 암상마다 함유된 방사성원소의 양이 다르다는 것을 이용하여 암상을 식별할 수가 있다(Asquith et al., 2004). 특히, 감마선 검층은 혈암(Shale, 셰일)을 다른 암상들과 구분하는데 사용된다. 전기비저항 검층 자료는 지중에 전류를 흘러 암상의 비저항 값을 측정하며, 이는 특히, 암상 속에 존재하는 유체(지하수, 탄화수소 등)에 대한 정보를 제공한다(Perdomo et al., 2014). 전기비저항 검층은 시추공으로부터 여러 거리에서 비저항 값을 측정하며, 크게 단거리, 중거리, 장거리로 나누어 측정한다.
공극률 검층은 지층 내 공극률을 측정하는 방법으로, 이를 위해 밀도 검층, 중성자 검층, 그리고 음파 검층이 수행된다. 이 중 밀도 검층은 검층 장비에서 방출된 감마선이 암상과 상호작용하는 과정에서 발생하는 콤프턴 산란 효과를 이용하여 암상의 전자 밀도를 측정하며, 이를 통해 다음과 같은 식으로 공극률을 계산할 수 있다.
여기서, 각 변수는 다음과 같다.
- ΦΦ: 공극률
- ρm: 암상 기질 밀도(암상의 고체 성분만을 고려한 밀도)
- ρb: 벌크 밀도(공극을 포함한 암상의 전체 밀도)
- ρf: 유체 밀도(공극을 채우고 있는 유체의 밀도)
즉, 식 (1)은 밀도 검층을 통해 얻은 암상의 벌크 밀도와 암상 기질 및 유체의 밀도 차이를 활용하여 공극률을 산정하는 원리를 나타낸다.
중성자 검층은 검층장비에서 방출되는 중성자들이 암상에서 흡수되지 않고 통과하는 양을 측정하여 암상 속에 존재하는 유체의 양을 측정한다. 밀도 검층과 중성자 검층을 같이 사용함으로써 지중에 존재하는 유체의 종류를 예측할 수가 있다. 음파 검층은 지중 내에 음파가 전달되는 속도를 측정하여 암상 및 공극률에 대한 정보를 제공한다(Naim et al., 2023).
Triple Combo Log 외에도, 필요에 따라 다양한 검층 자료를 Triple Combo Log로부터 도출할 수 있으며, 대표적으로 셰일 함량, 수포화도, 유효 공극률 등이 포함된다. 셰일 함량은 암상 내 존재하는 셰일의 비율을 의미하며, 다음과 같은 식을 통해 계산된다(Kamel et al., 2003).
여기서, 각 변수는 다음과 같다.
- Vsh: 셰일 함량
- GR: 감마선 검층 값
- GRmin: 감마선 검층 최솟값
- GRmax: 감마선 검층 최댓값
즉, 식 (2)는 감마선 검층을 활용하여 암상 내 셰일 함량을 추정하는 방법을 나타내며, GR 값이 증가할수록 셰일 함량이 높아지며, Vsh 값이 1에 가까울수록 해당 암상이 셰일에 가까운 성질을 가짐을 의미한다.
수포화도는 암상의 공극 내 존재하는 물의 비율을 나타내며, 이를 계산하기 위한 다양한 방법이 존재한다. 본 연구에서는 Archie의 식을 적용하여 다음과 같이 계산된다(Guo et al., 2021).
여기서, 각 변수는 다음과 같다.
- Sw: 수포화도
- a: Archie의 상수
- m: 시멘트화 지수
- n: 포화도 지수
- Rw: 지하수의 전기비저항 값
- Rt: 해당 암상의 전기비저항 값
- Φ: 공극률
즉, 식 (3)은 수포화도를 비저항과 공극률을 이용해 계산하며, Sw 값이 높을수록 지층 내 물의 함량이 높고, 낮을수록 유체(석유 또는 가스) 함량이 높은 것을 의미한다.
유효 공극률(Φe)은 암상의 총 공극 중에서 유체가 이동할 수 있는 공극의 비율을 의미하며, 이는 식 (1)과 (2)를 이용하여 다음과 같이 산출된다(Stephens et al., 1998).
자기조직화 지도(Self-Organizing Map, SOM)
자기조직화 지도(Self-Organizing Map, SOM)는 Kohonen (1990)이 제안한 인공신경망의 한 유형으로, 고차원 데이터를 저차원 공간으로 변환하여 시각화하는 동시에 군집화를 수행하는 비지도 학습 기반의 분류 기법이며, 이에 대한 구조는 Fig. 1과 같다. SOM은 크게 입력층과 출력층으로 구성되며, 출력층의 각 노드에는 가중치 벡터가 할당된다. 훈련 과정에서 입력 데이터에 따라 가중치 벡터가 점진적으로 갱신되며, 훈련이 완료되면 최종적으로 학습된 가중치 벡터들이 입력층의 데이터(입력 벡터)를 대표하는 구조를 형성하게 된다.
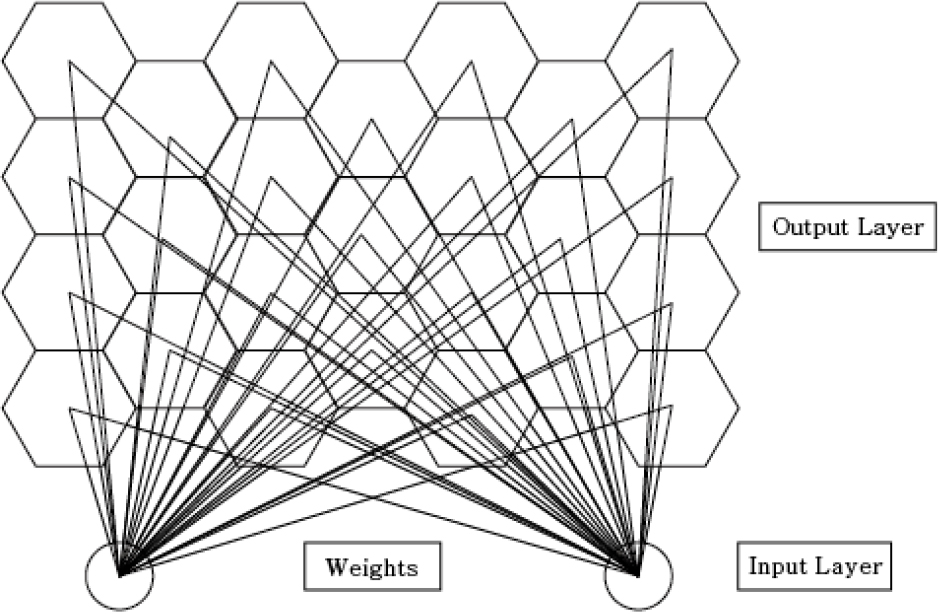
SOM의 훈련 과정은 다음 단계로 구성된다.
1. 초기화: 출력층의 각 노드에 해당하는 가중치 벡터(W)의 요소값을 임의로 설정한다.
2. 거리 계산: 입력 벡터(I)와 각 노드의 가중치 벡터 간의 거리를 측정한다. 일반적으로 유클리드 거리를 사용하여 계산한다.
3. BMU (Best Matching Unit) 탐색: 입력 벡터와 가장 유사한 가중치 벡터를 가진 노드를 찾으며, 이를 Best Matching Unit (BMU)라고 한다.
4. 가중치 갱신: 각 노드의 가중치 벡터는 반복마다 다음과 같은 공식을 통해 갱신된다.
여기서, =이웃 반경, 학습률, 과 이웃 반경 내에 위치한 가중치 벡터와의 거리
5. 훈련 종료: 위의 2~4 과정을 반복하며, 갱신된 가중치 벡터 값이 일정 범위 내에서 변동하지 않으면 훈련을 종료한다.
SOM 앙상블(SOM 100)
SOM 알고리즘은 초깃값이 임의로 설정되므로, 매 훈련 과정마다 서로 다른 클러스터링 결과가 도출될 가능성이 크다. 이를 방지하기 위해 random seed라는 변수를 일정한 값으로 고정하여 매 훈련마다 동일한 클러스터링 결과를 생성하도록 설정할 수 있다. 이는 안정된 군집을 보장하지만 최적의 결과를 보장하지는 않는다(Shkaberina et al., 2022).
본 연구에서는 이를 개선하기 위해 SOM 앙상블 기법을 개발하였다. 앙상블 기법은 여러 기계 학습 모델의 예측 결과를 결합하여 보다 정확한 결과를 도출하는 방법으로, 이를 SOM 모델에 적용하였다. 구체적으로, 서로 다른 random seed 값을 사용하여 100개의 독립적인 SOM 모델(SOM 100)을 훈련하고, 각 입력 데이터에 대해 100개의 군집 결과를 도출하였다. 이후, 다수의 SOM 모델이 예측한 군집 결과를 최종 결과로 결정하는 방식을 적용하였다. 이러한 방법은 앙상블 학습에서 직접 투표 기법으로도 알려져 있다(Mohammed and Kora, 2023).
결 과
입력 변수 선택(Feature Selection) 및 데이터 전처리
본 연구에서는 물리검층 자료를 활용하여 암상 분류를 위한 SOM 모델을 학습시키기 위해 총 7개의 입력 변수 조합을 다음과 같이 선정하였다.
- GR, DENS, Φe
- GR, NEUT, Φe
- GR, SONI, Φe
- GR, DENS, NEUT, Φe
- GR, DENS, SONI, Φe
- GR, NEUT, SONI, Φe
- GR, DENS, NEUT, SONI, Φe
감마선 검층(GR), 밀도 검층(DENS), 중성자 검층(NEUT), 음파 검층(SONI), 유효 공극률 검층(Φe)은 암상을 식별하고 분류하는 데 대표적으로 사용되는 자료이므로 포함하였으며, 비지도 학습의 특성상 최적의 조합을 확인하기 위해 다양한 조합을 실험하였다. 또한, 전기비저항과 수포화도는 암상의 특성보다는 유체의 영향을 반영하므로 Feature Selection 과정에서 제외하였다. 선택된 입력 변수를 활용하여 총 5개의 암상을 식별하고 분류하였으며, 각 암상은 분석의 일관성을 위해 정수 값 1~5로 정의되었다.
군집 분류 결과
Fig. 2에서 확인할 수 있듯이, random seed 값이 달라짐에 따라 SOM 클러스터링 결과가 변하는 것을 확인할 수 있다. 이를 개선하기 위해, 본 연구에서는 개발된 SOM 100 모델을 활용하여 Feature Selection 과정에서 선택된 7개의 변수 조합을 SOM 100 모델에 학습시켜 암상을 분류하도록 훈련하였다.
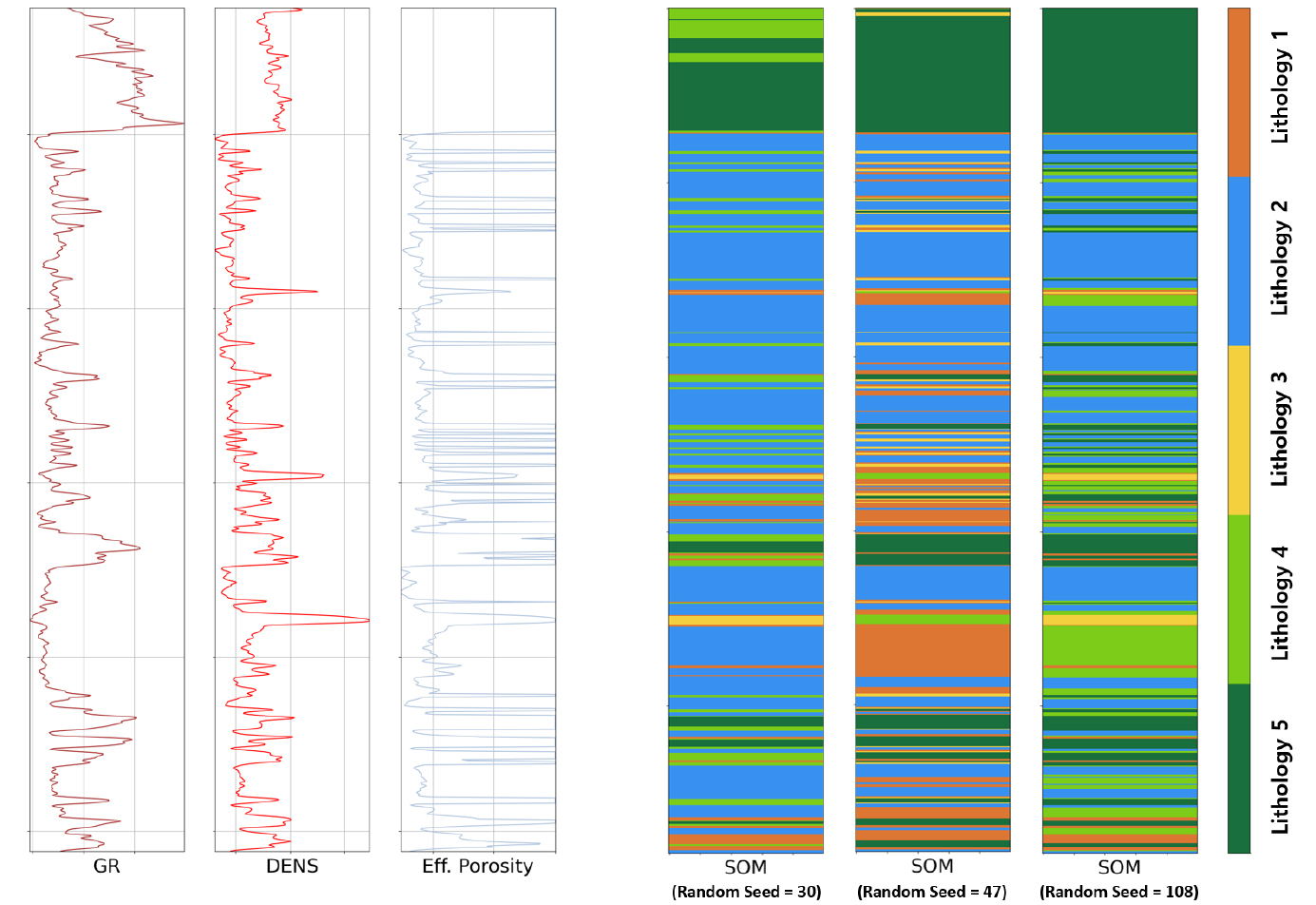
모델의 성능 평가를 위해, 주어진 물리검층 자료와 해당 층의 암상 데이터를 활용하여 암상 분류 결과의 정확도를 측정하는 알고리즘을 개발하였다. 비지도 학습을 통해 얻은 군집 결과는 레이블링이 랜덤하게 부여되므로, 이를 정확하게 비교분석하기 위해 주어진 암상 데이터와의 매칭 과정을 거쳤다. 가능한 모든 군집 매칭 경우의 수를 고려하여, 군집 레이블을 주어진 데이터와 최대한 유사하게 정렬한 후 오차가 최소화되는 군집 분류를 도출하였다. 이후, 도출된 군집 결과를 정답 자료와 비교하여 정확도를 산출하였다. Table 1과 2는 각각 단일 SOM 모델과 SOM 100 모델의 예측 정확도를 나타낸다.
Table 1.
Accuracy of the single SOM model for each feature pair input.
| Input features | Accuracy |
| GR, DENS, Φe | 0.751 |
| GR, NEUT, Φe | 0.781 |
| GR, SONI, Φe | 0.778 |
| GR, DENS, NEUT, Φe | 0.780 |
| GR, DENS, SONI, Φe | 0.779 |
| GR, NEUT, SONI, Φe | 0.746 |
| GR, DENS, NEUT, SONI, Φe | 0.696 |
Table 2.
Accuracy of the SOM 100 for each feature pair input.
| Input features | Accuracy |
| GR, DENS, Φe | 0.816 |
| GR, NEUT, Φe | 0.796 |
| GR, SONI, Φe | 0.802 |
| GR, DENS, NEUT, Φe | 0.794 |
| GR, DENS, SONI, Φe | 0.792 |
| GR, NEUT, SONI, Φe | 0.800 |
| GR, DENS, NEUT, SONI, Φe | 0.776 |
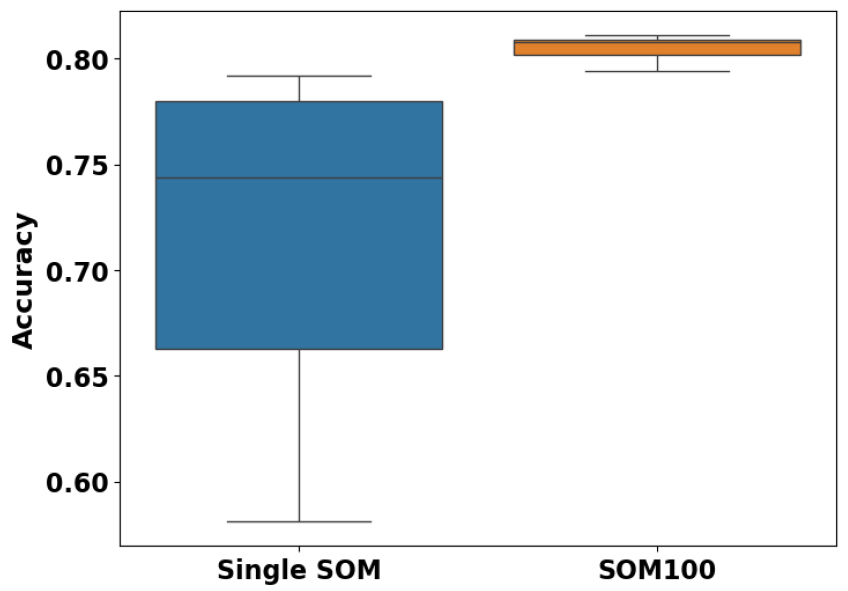
Table 1과 2를 분석한 결과, 모든 입력 변수 조합에 대해 SOM 100 모델을 활용함으로써 단일 SOM 모델보다 예측 정확도가 향상되었음을 확인할 수 있었다. 또한, Fig. 3은 다양한 random seed 값을 적용한 경우의 예측 정확도 값의 범위를 나타내며, 단일 SOM 모델을 사용한 경우 예측 정확도 값의 변동성이 매우 큰 것으로 나타났다. 반면, SOM 100 모델에서는 예측 정확도의 변동성이 감소하였으며, 이를 통해, 안정성 측면에서도 SOM 100 모델이 보다 우수함을 확인할 수 있다.
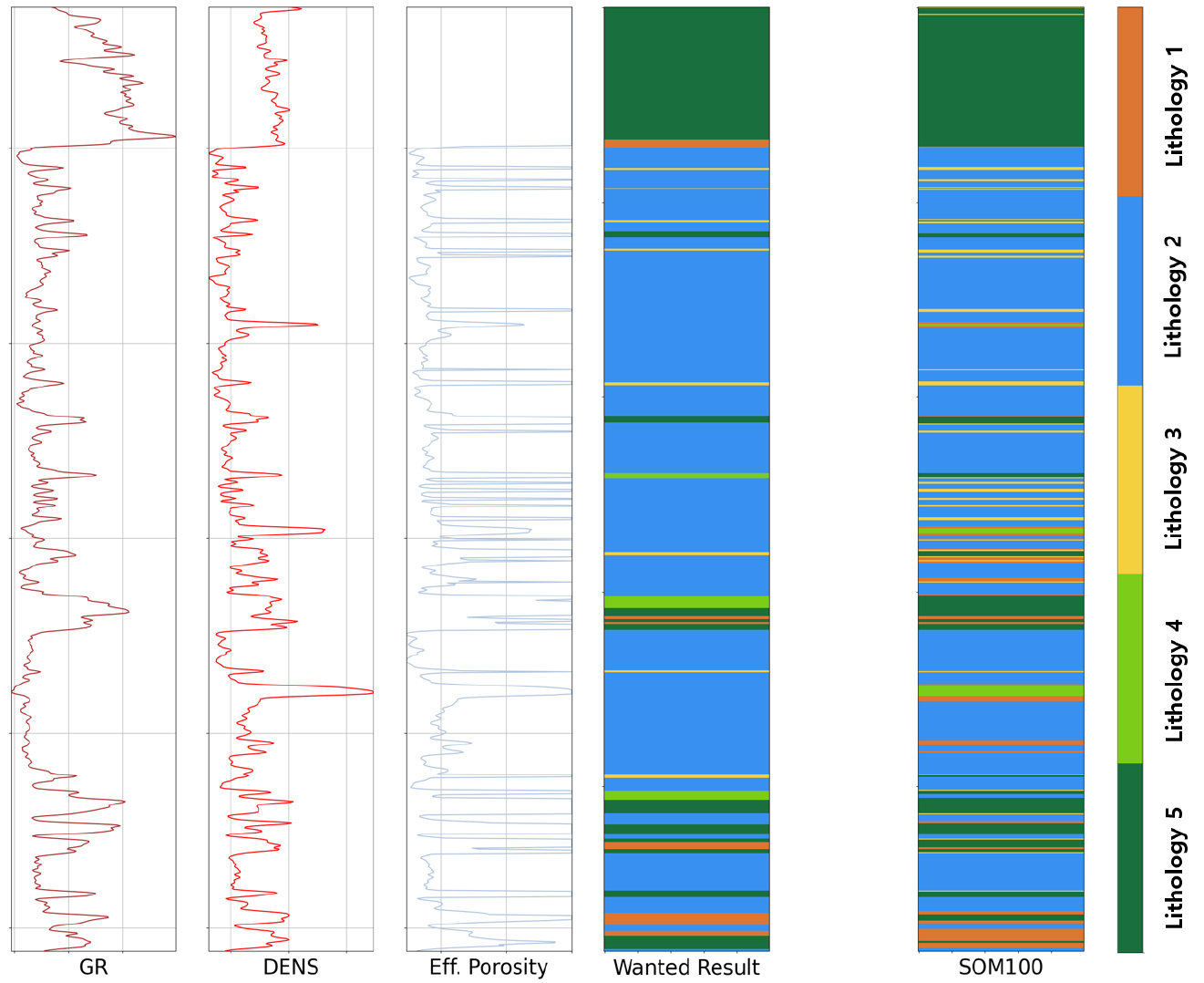
예측 정확도가 가장 높게 나타난 결과(Fig. 4)를 분석한 결과, 정답 자료에서는 암상의 변화가 비교적 적으며, 명확한 층서적 구분이 이루어지고 있음을 확인할 수 있다. 반면, SOM 100 모델의 예측 결과에서는 암상 변화가 빈번하게 발생하고, 층서적 연속성이 유지되지 않은 채 과도하게 세분화된 군집이 형성되었다. 이는 과도한 군집화(Overclustering) 현상이 발생했음을 시사하며, 전체 암상 수에 비해 검층 자료의 데이터 값 변동성이 전반적으로 매우 높아 지질학적 연속성이 충분히 반영되지 못했음을 의미한다. 이러한 경향은 다른 입력 변수 조합에서도 일관되게 나타나는 것으로 확인되었다(Fig. 5).
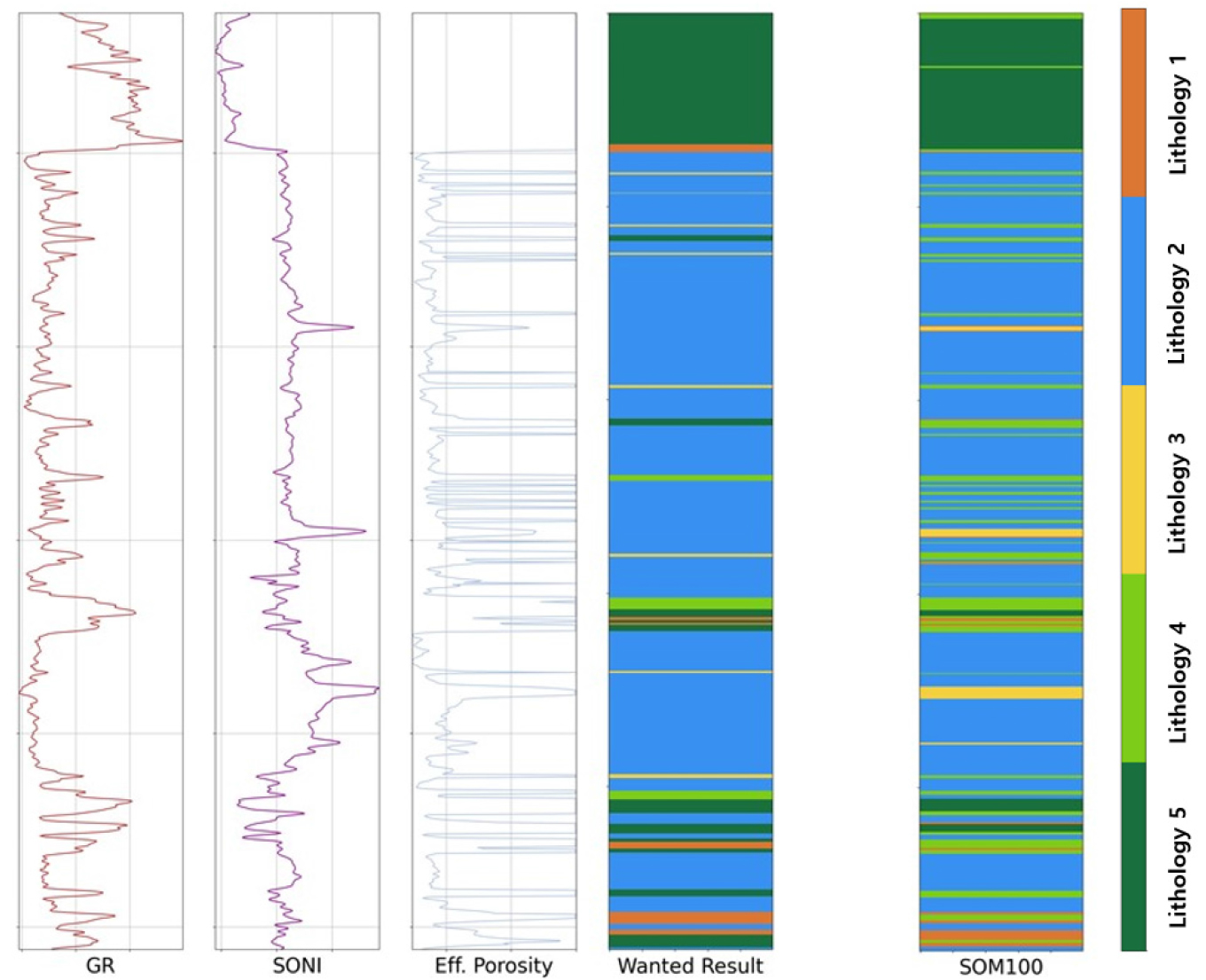
결 론
본 연구에서는 자기조직화 지도(Self Organizing Map, SOM) 알고리즘을 활용하여 물리검층 자료로부터 암상을 분류하고, 이를 사전에 제공된 암상 자료와 비교하여 예측 정확도를 평가하였다. 그러나 단일 SOM 모델을 사용할 경우 안정성이 떨어지는 문제가 존재하므로, 이를 개선하기 위해 서로 다른 random seed 값을 적용한 100개의 SOM 모델을 결합하는 앙상블 기법을 도입하였다.
그러나 SOM 100 모델은 여전히 몇 가지 한계를 가진다. 첫째, 과도한 군집화 문제를 완전히 해결하지 못하였다. 이는 결과에서 논의한 바와 같이, 물리검층 자료 값의 범위가 넓어 모델이 상대적으로 높은 값들을 독립적인 군집으로 배정하는 경향이 있기 때문으로 판단된다.
둘째, 비지도 학습 모델의 특성상, 일반적으로 사전에 총 군집 수를 알 수 없다. 따라서 최적 군집 수를 먼저 결정한 후 이를 비지도 학습 모델에 입력해야 하지만, 본 연구에서는 총 군집 수가 사전에 주어진 상태에서 알고리즘을 개발하였다. 이는 본 알고리즘을 다른 지역에 적용하는 데 있어 제약이 될 수 있다.
그럼에도 불구하고, 본 연구는 기존 연구와 달리 암상 정보가 사전에 제공된 환경에서 알고리즘을 개발함으로써 모델을 더욱 발전시킬 가능성을 제시하였다. 향후 연구에서는 총 군집 수를 모른다는 가정하에 모델을 학습시켜, 모델이 자체적으로 군집 수를 결정하고 군집화 과정을 수행할 수 있도록 개선하는 것이 필요하다.
