

서 론
국내 이산화탄소 지중저장을 위한 핵심 기술 확보를 위해 포항분지 중소규모 CO2 저장 실증 사업이 경상북도 포항시 영일만 해상에서 수행되었다(Kwon, 2018). 이 사업의 일환으로 영일만의 포항분지 퇴적층에 주입될 이산화탄소 거동 모니터링(monitoring) 탐사를 위해 해저면에 OBN (Ocean Bottom Node)이 2차원적으로 배열되었다. 그리고 3차원 탐사의 가능성을 타진하고 주입 이후 모니터링의 기준(baseline)이 될 수 있는 자료를 얻기 위해 주입 전인 2016년에 3차원 탐사가 진행되었다. 그러나 탐사 지역은 수심이 얕고 인근에 방파제가 있으며 상선이 수시로 운행하는 해역으로, 이런 탐사환경으로 인해 취득된 자료는 낮은 신호 대 잡음비를 갖고 있다. 이와 같은 탄성파 탐사 자료에 포함된 잡음들을 효과적으로 제거하기 위해서는 f-k 필터링, 다중반사파 제거(SRME; Surface Related Multiple Elimination) 등과 같이 격자(grid) 기반 자료처리 방법들의 적용이 필요하며, 이를 위해서는 송·수신기 위치가 불규칙하게 얻어진 자료의 정규화(regularization)가 필요하다.
일반적인 3차원 탄성파 자료의 경우 비닝(binning)을 통해 정규화를 수행하지만, 이 연구에 사용된 현장 자료는 OBN을 이용한 소규모 탐사 자료이므로 송신 음원과 수신 노드(node)의 수가 매우 적다. 또한 탐사 시 환경적 제약으로 인해 측선 간격이 일정하지 않아 비닝 결과에 부정적인 영향을 끼치게 된다.
비닝의 결과를 향상시키기 위한 트레이스 정규화 방법은 꾸준히 연구되어 왔지만(Liu and Sacchi, 2004; Abma and Kabir, 2006; Xu et al., 2010), 최근에는 비선형적인 자료 특성을 효과적으로 학습할 수 있는 딥러닝(deep learning) 기반의 정규화 기법이 활발하게 연구되고 있다(Wang et al., 2020; Kaur et al., 2021; Greiner et al., 2022). 대부분의 딥러닝 기반 정규화 기법은 2차원 모음(gather) 형태의 자료를 사용하며 결측(missing)이 포함된 자료를 입력(input)으로, 완전한 자료를 정답(label)으로 하여 모델을 학습시킨다. 그러나 이러한 2차원 모음 기반 접근법은 각각의 트레이스(trace)의 실제 위치를 그대로 사용하는 것이 아니라 정규화 된 격자로 이동시킨 후 결손된 위치를 내삽(interpolation)을 통해 정규화 하는 방식이므로, 공간 정보가 왜곡될 수 있다는 한계가 있다. 더 정확한 위치 정보를 반영하기 위해 Mo et al. (2025)은 불규칙한 위치 정보를 유지한 채 직접 정규화 된 위치를 재 생성할 수 있는 NDFT (Non-uniform Discrete Fourier Transform)를 이용해 입력 자료를 구성하여 딥러닝 모델을 학습시키는 방법을 제시하였다. 그러나, 이 경우 모델 학습 시 현장자료와 비슷한 대규모의 합성(synthetic) 모음 자료를 먼저 생성한 후 이 학습자료를 이용한 학습이 선행되어야 한다는 단점이 있다. 한편, 동일 측선(survey line) 상에서 얻어진 자료를 기반으로 하는 2차원적인 접근은 3차원적으로 분포하는 자료들을 효과적으로 다루는데 한계를 보이기 때문에 3차원 큐빅(cubic) 형태의 입력 자료를 사용하는 내삽 기법도 제안되었으나(Saad et al., 2023), 이 경우는 학습을 위한 많은 컴퓨터 메모리(memory)와 비용이 들며 앞선 방법과 동일하게 딥러닝 모델 학습을 위해 많은 자료의 생성이 필요하다는 문제점이 있다.
이러한 제약을 극복하기 위한 방안으로, Yeeh (2024)는 델로네이 공간분할(Delaunay tessellation)을 이용한 딥러닝 기반의 3차원 트레이스 정규화 기법을 제안하였다. 이 방법은 근방의 세 트레이스와 각각의 위치 정보만을 이용하여 정규화 될 위치의 트레이스를 예측하는 방법으로, 탐사 시 취득된 송수신기의 위치를 매우 자유롭고 유연하게 사용할 수 있으며, 현장자료를 이용하여 학습을 진행하여 복잡한 합성 자료의 생성 없이 현장 자료의 특성을 그대로 학습시킬 수 있다. 특히 이 정규화 방법은 학습 시에는 (비정규 격자 → 비정규 격자)를, 예측 시에는 (비정규 격자 → 정규 격자)의 자료를 다루는 방법으로, 취득된 송수신 배열의 간격에 국한되지 않고 원하는 정규화 위치 근방의 국소적인 정보를 활용하여 정규화 될 위치의 자료를 예측함으로써 내삽과 정규화를 동시에 수행할 수 있으므로, 이 연구에 사용된 소규모의 불규칙한 자료에 적합한 방식이다.
따라서 이 연구에서는 불규칙한 간격의 송신위치와 적은 수의 수신 노드로 인해 다소 불규칙하고 넓은 간격으로 취득된 포항 OBN 자료의 송신기 자료에 Yeeh (2024)의 딥러닝 기반 3차원 정규화 기법을 적용한 사례를 소개하고자 한다. 먼저 정규화 목표 자료가 얻어진 지역의 지형학적, 지질학적 특징을 소개하고, 적용할 정규화 방법을 알맞게 적용하기 위해 포항 현장 자료의 특성을 분석하였다. 다음으로 분석된 자료와 사전정보를 바탕으로 딥러닝 모델의 학습 성능을 높일 수 있는 학습 자료를 만들기 위한 전처리(preprocessing) 과정에 대해 기술하였다. 또한, 합리적인 모델 생성을 위한 학습 자료의 구성 방안에 대해서도 고찰하였다. 마지막으로 선별한 학습 자료로 학습된 딥러닝 모델을 이용하여 정규화 위치들의 트레이스를 예측하고 그 결과에 대해 고찰하였다. 추가적으로, 현장 자료 적용을 통해 알게 된 Yeeh (2024)의 딥러닝 기반 3차원 정규화 기법의 제약 사항과 이 연구에서 적용한 송신기 자료의 정규화가 아닌 OBN 수신기 자료의 정규화 적용 가능성에 대해서도 기술하였다.
연구 지역 및 탐사 정보
연구 지역은 한반도 남서부 포항시 영일만 해역의 포항 분지에 위치한다(Fig. 1). 이 퇴적분지는 신생대 마이오세에 형성되었으며 동쪽으로 갈수록 깊은 해양성 환경이 우세한 퇴적층으로서 서쪽에서 동쪽으로 점진적으로 깊어지는 경향을 보인다(Noh, 1994; Lee et al., 2009). 이 지역은 중소규모의 CO2 지중저장을 위해 선정된 곳으로, Shinn et al. (2018)은 이 지역이 해수면 기준 심도 650~950 m에 분포하는 화산암을 기반암(Basement, BST)으로 가지며, 기반암 상부의 퇴적층은 두 개의 탄성파 단위층(Seismic Unit, SU)으로 구분된다고 하였다. 여기서 하부의 단위층인 SU-1은 하성 또는 삼각주 환경에서 퇴적된 조립질 퇴적층으로 상부 경계면 심도가 약 550~830 m에 분포하며 두께가 약 60~170 m, 평균 두께가 약 123 m로 이산화탄소 주입층에 적합하고, 상부의 단위층인 SU-2는 해양 부유성 퇴적물과 얇은 저탁류 사암으로 구성된 세립질 퇴적층을 가져 덮개암에 적합한 것으로 해석하였다(Fig. 2).
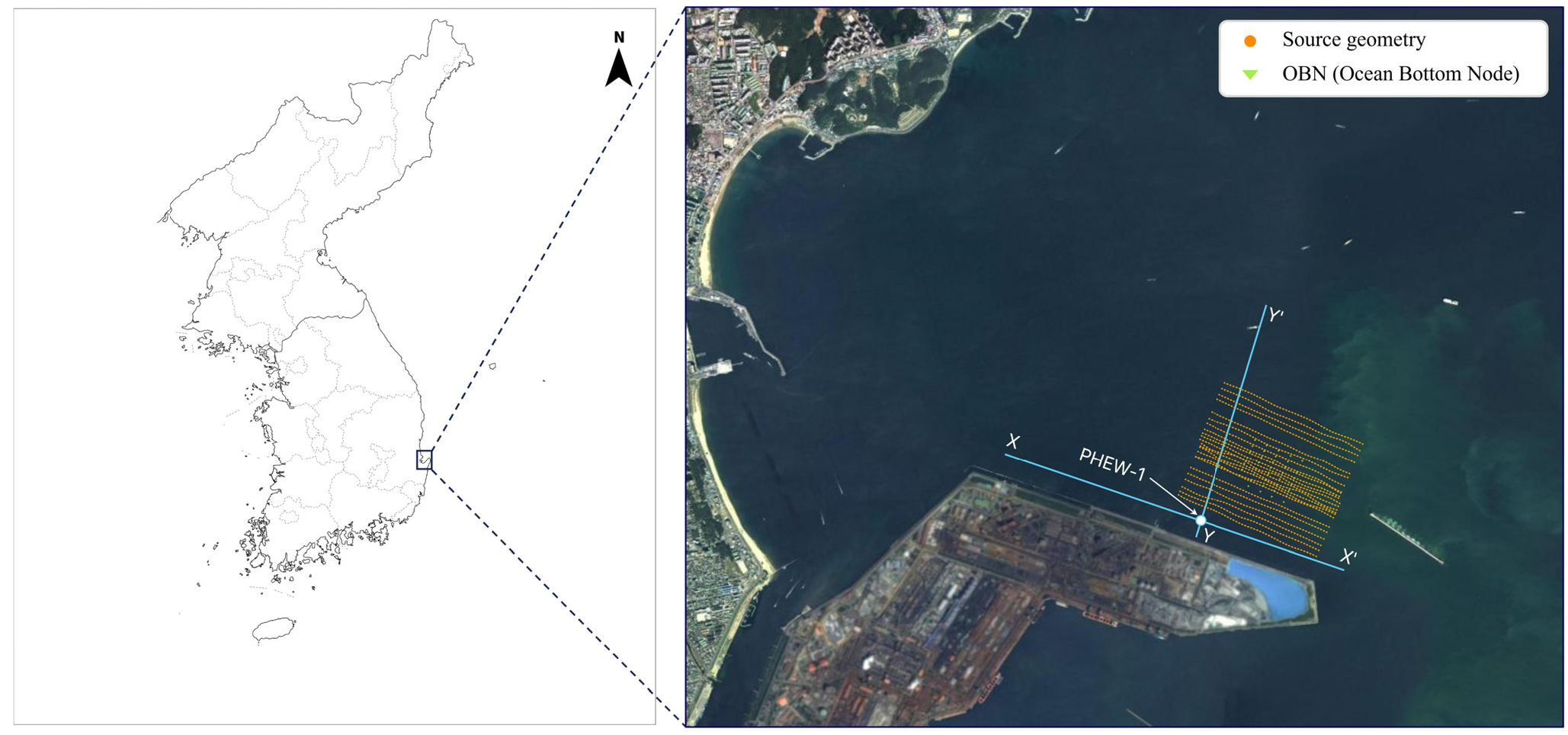
Fig. 1
Location map of the study area (Source: National Geographic Information Institute, 2024, 2025)).
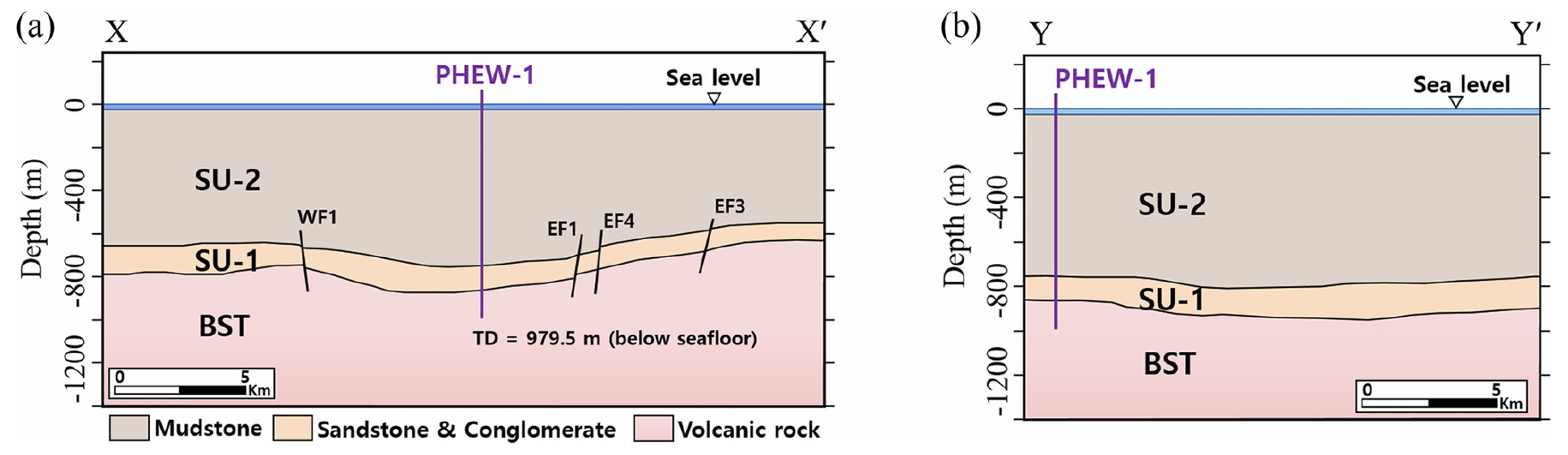
Fig. 2
Depth structure map of the study area along (a) XX’ and (b) YY’ lines in Fig. 1 (taken from Park et al., 2021). PHEW-1 (open circle in Fig. 1) indicates the location of the well.
이 연구지역에서 한국지질자원연구원은 이산화탄소 주입 전후 모니터링을 위한 기준 탐사를 목적으로 2016년 3월 27일부터 4월 1일까지 3차원 OBN 탐사를 수행하였다(Park et al., 2018). 이는 국내에서 최초로 수행된 3차원 OBN 탄성파 탐사이며, 탐사자료의 시간 간격(∆t)은 0.976 ms이고 총 기록 시간(tmax)은 5.995568 sec이다. 수진기는 국내 업체인 AAT에서 개발한 2채널 OBN인 Hydro-Geophone OBS (Ocean Bottom Sensor)가 사용되었으며, 이 연구에서는 하이드로폰(hydrophone)으로 취득된 자료를 사용하였다. 수신 노드의 배열은 총 40개의 OBN을 인라인(Inline) 방향으로 5개 노드가 100 m 간격으로, 인라인과 수직인 크로스라인(Xline) 방향으로 8개 노드가 50 m 간격으로 설치되어 8×5의 배열로 구성되었다(Fig. 3). 이 중 두 개 노드는 취득 불량으로 제외되어 총 38개 노드에서 취득된 탄성파 자료를 분석할 수 있었다. 음원으로는 이산화탄소 주입 예정층 심도인 약 1 km 내외를 충분히 투과할 수 있는 269 in3의 에어건(airgun)이 사용되었다(Kwon, 2018). 송신원 배열은 탐사지역이 수심이 15~17 m의 매우 낮은 천해이며, 인근에 포항제철 방파제가 위치하는 상선과 어선이 수시로 운항하여 조밀한 발파가 어려운 해역이므로 Fig. 3과 같이 50 m 측선간격으로 측정하고 중심부에 4개의 측선을 추가로 발파하여 총 25개의 측선에 대한 자료를 취득하였다. 그러나 이 중 2개의 측선은 GPS측정된 측선의 위치 정보가 불명확하여 연구에는 23개 측선의 송신자료가 사용되었다. 한 인라인 측선 당 발파수는 25 m 간격을 갖는 총 48개로 총 송신원 수는 1104 (=23×48)개이다.
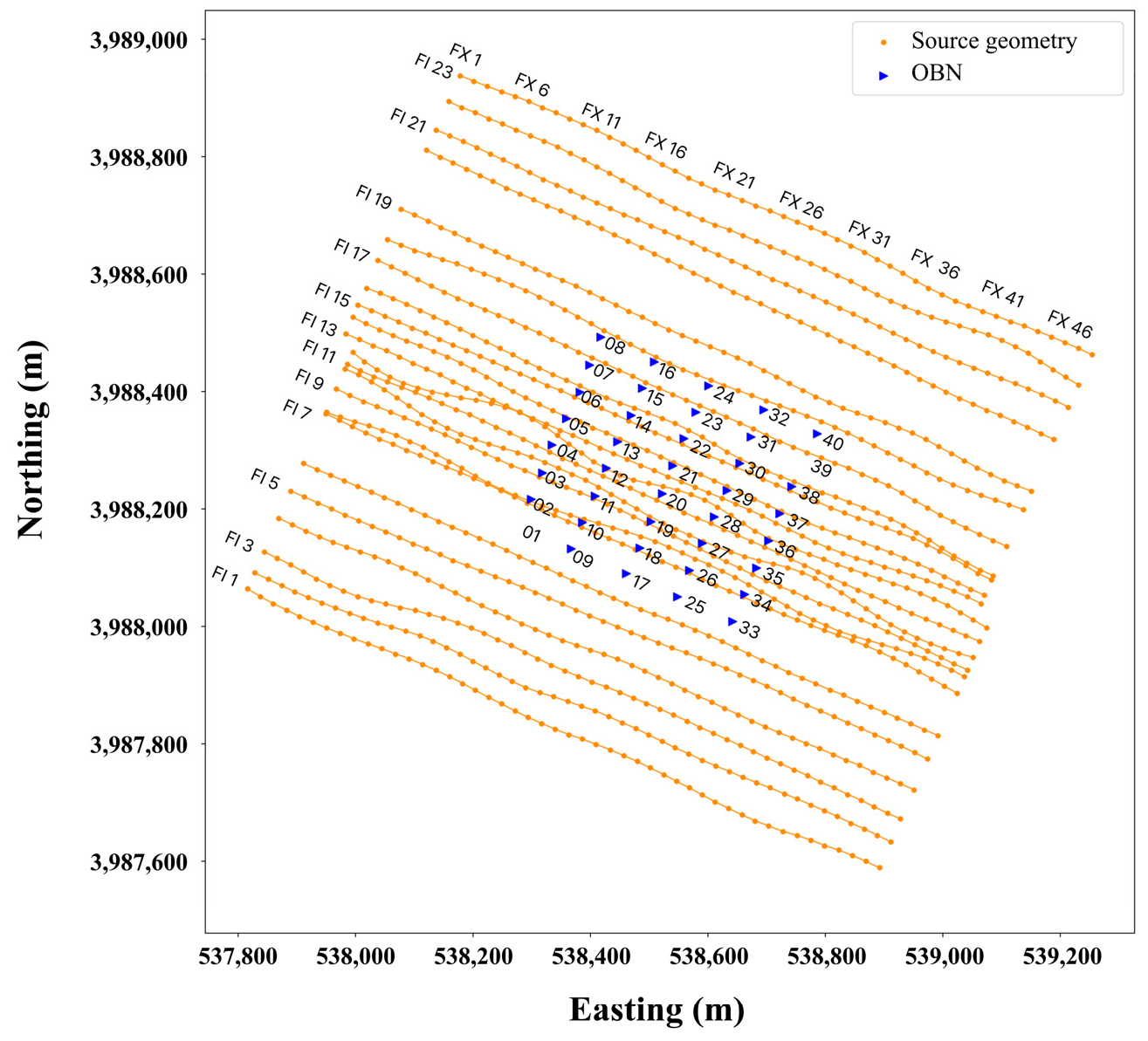
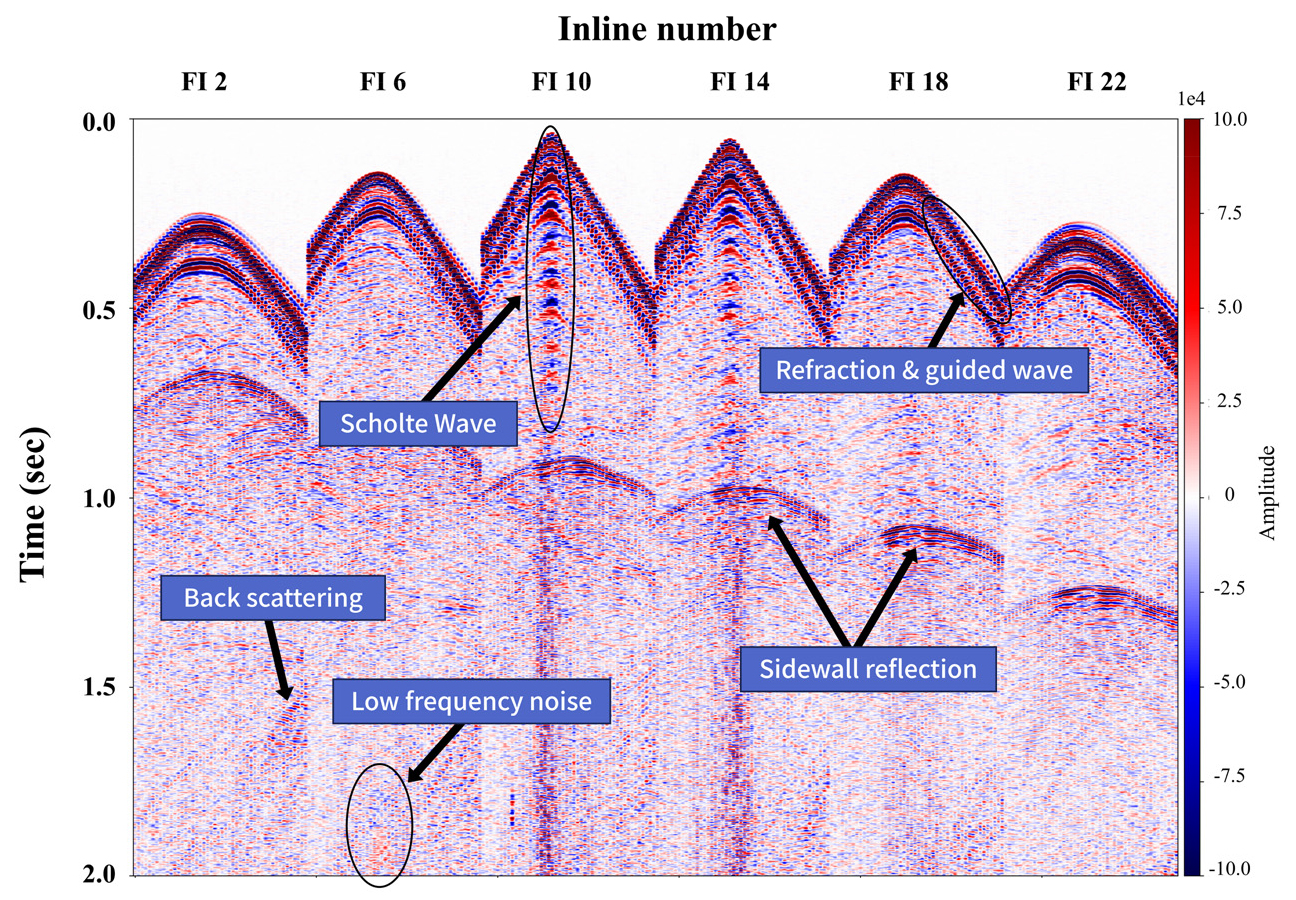
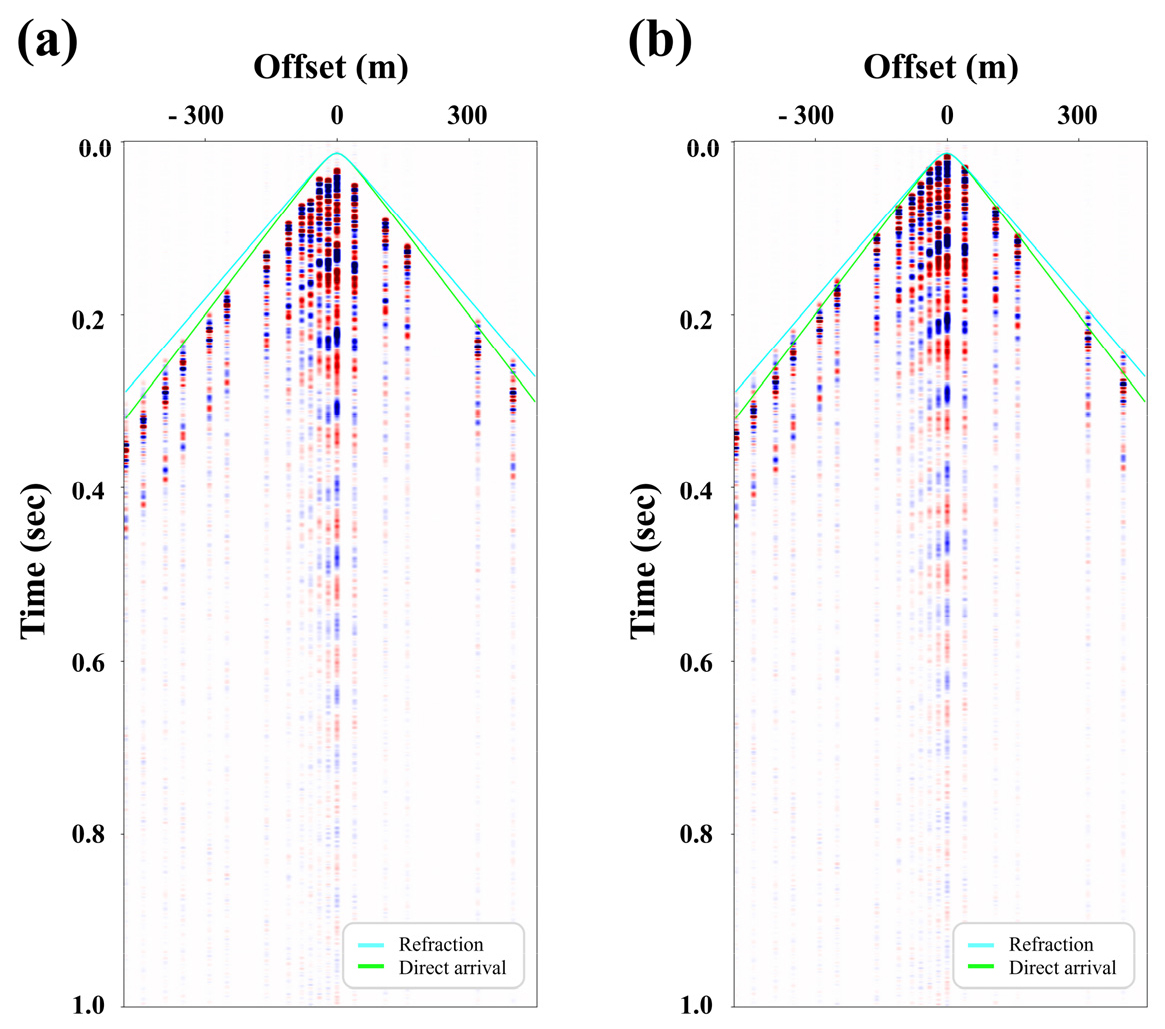
Fig. 4에 탐사 지역 OBN 12번에서 측정된 공통 수신기 모음(CRG; Common Receiver Gather) 자료를 도시하였다. 앞서 기술한 대로 이 지역에서 얻어진 자료에는 낮은 수심과 주변지역의 특성으로 인해 다양한 잡음이 포함되어 있다. 대표적으로 낮은 수심으로 인해 발생된 강한 Scholte wave 및 다중반사파, 수면층에 반복적으로 반사된 가이드파(guided wave), 선박에 의한 국소적 잡음, 방파제에서 반사된 측면(sidewall) 반사파와 후방산란(back scattering) 현상 등이 있다(Park et al., 2018). 이러한 잡음들을 효과적으로 제거하기 위해서는 서론에서 기술한 바와 같이 일정한 간격으로 얻어진 격자 기반의 자료처리를 거쳐야 하며, 따라서 불규칙하게 얻어진 송신기 자료의 정규화가 필요하다.
딥러닝 기반 다차원 트레이스 정규화 기법
Yeeh (2024)의 다차원 트레이스 정규화 방법은 입력 자료 및 정답 자료 생성, 모델 학습, 학습된 모델을 이용한 예측 순서로 구성된다. Fig. 5에서와 같이 현장 자료가 XY평면상에 불규칙하게 분포할 때, 먼저 정규화에 사용할 트레이스 선택 시 최대 거리의 기준이 되는 반경 R-value를 설정해 준다. 다음으로 이 평면 상의 임의의 지점을 선정하고, 이 점을 중심으로 반경 R-value를 갖는 원 안에 위치하는 자료 중 무작위로 4 개를 선택한다. Fig. 6(a)와 6(b)에 선택된 네 점의 좌표로 만든 볼록 껍질(Convex hull)이 가질 수 있는 두 경우를 나타내었다. 볼록 껍질은 주어진 점들을 연결해서 만들 수 있는 가장 작은 볼록 도형으로, 여기서 볼록 도형이라 함은 도형 내 임의의 두 점을 이었을 때 그 선분 전체가 항상 도형 내부에 포함되는 도형을 의미한다. 따라서 평면 상의 네 점을 선택할 경우 볼록 껍질이 사각형(Fig. 6(a)) 혹은 삼각형(Fig. 6(b))이 될 수 있으며, 삼각형인 경우 나머지 한 점은 도형 내부에 존재함을 알 수 있다. 학습 자료 생성 시에는 볼록 껍질이 삼각형인 경우만을 학습 자료로 채택하며 이렇게 선택된 네 개의 점 중 삼각형의 세 꼭지점에 해당되는 자료는 입력 자료, 내부의 한 점은 정답 자료로 사용된다. 이 때, 세 트레이스를 이용하여 내부의 한 트레이스를 예측하기 위해서는 삼각형 내에서의 정답 자료의 위치 정보가 필요하므로 면적 기반 가중치인 중심 좌표(Barycentric coordinates; Möbius, 1827) 또한 입력 자료로 사용된다. Fig. 6(c)에서 볼 수 있듯 입력 자료의 위치를 각각 A, B, C, 정답 자료의 위치를 Q라고 할 때, 각 입력 자료의 위치에 대한 중심 좌표는 식 (1)과 같이 네 점이 이루는 세 삼각형들의 면적비로 표현할 수 있고, 이 가중치는 입력 자료와 정답 자료의 거리가 멀수록 면적에 기반해 감소함을 알 수 있다.

Fig. 5
A schematic diagram illustrates the process of selecting four points with a given R-value from an irregularly distributed 3-D field data (marked with blue crosses). The area for selecting traces centered at an arbitrary point x with a radius of R-value is shown as a violet circle and four selected traces are marked with black arrows.
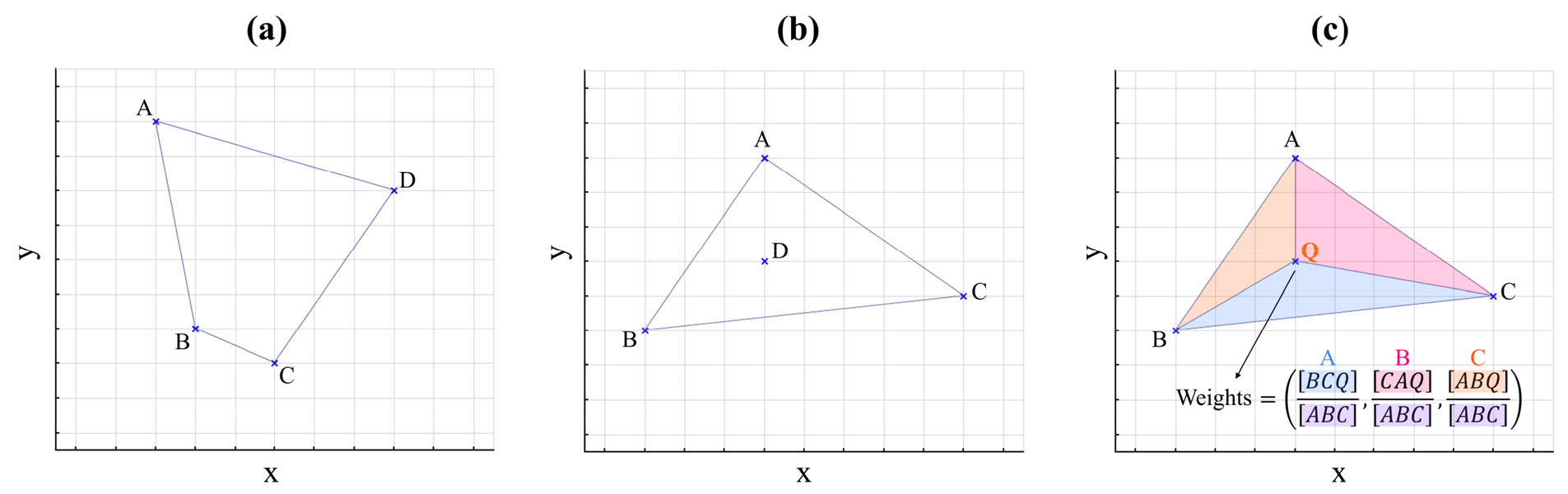
Fig. 6
Example of the geometries of four selected points and a conceptual diagram of the Barycentric coordinate. (a) The case where the convex hull is a rectangle which cannot be used for an input-label pair, (b) the case where the convex hull is a triangle which can be used for an input-label pair, and (c) calculated weights using Barycentric coordinates for the input-label pair selected in (b).
앞선 과정을 원하는 입력-정답 자료쌍의 개수를 충족할 때까지 반복하면 학습 자료 생성이 완료된다. 이 과정에서 가장 중요한 것은 입력 자료로부터 합리적으로 추론될 수 있는 정답 자료의 쌍을 생성하는 것이므로, 현장 자료의 특성에 따라 적절한 R-value를 선택하도록 유의해야 한다.
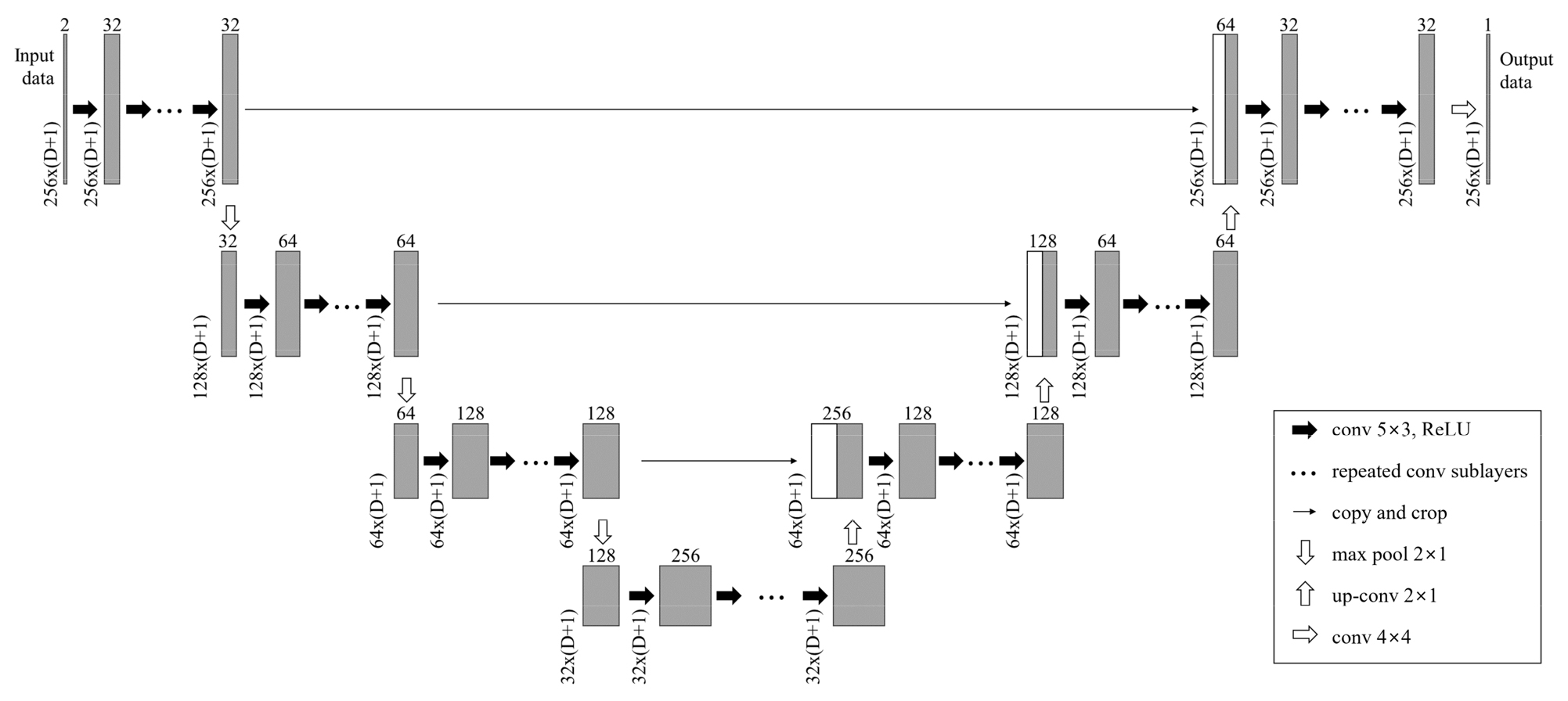
생성된 학습 자료의 트레이스들은 일정한 시간 길이로 잘린 패치(patch) 단위로 분할된 후 U-Net 모델을 통해 학습된다(Fig. 7). 학습이 완료된 딥러닝 모델은 현장 자료로부터 원하는 위치의 트레이스를 예측하는 데 사용되며, 이때 예측에 사용되는 입력 자료의 면적 가중치는 Yeeh (2024)에 소개된 대로 델로네이 공간분할을 통해 삼각형으로 분할된 현장 자료의 위치와 정규화 할 지점의 위치를 이용해 생성된다. 델로네이 공간분할은 D차원 공간에 분포하는 점들의 집합을 델로네이 기준에 적합한 D-simplex들로 분할하는 방법이다(Lee and Schachter, 1980). Simplex는 D차원 공간에서 D+1개의 꼭짓점을 갖는 볼록 도형이므로, X-Y 평면상에 분포하는 점들인 2차원의 경우 삼각형이 된다. 델로네이 공간분할을 사용하면 2차원 공간에 분포하는 점들의 집합을 겹치지 않는 삼각형으로 나눌 수 있으며, 이렇게 분할된 결과는 삼각형의 내각 중 가장 작은 각이 최대한 커지도록 구성되므로 2차원 점의 집합을 삼각형으로 나눌 수 있는 경우 중 가장 정삼각형에 가까워 구조적으로 안정적인 분포를 이루도록 해준다. Fig. 8에 도시한 것과 같이, 각각의 정규화 위치에서 삼각 분할된 현장 자료의 트레이스와 중심 좌표를 예측 입력 자료로 구성하면 주변의 세 개 트레이스만을 활용한 3차원 트레이스 정규화를 모든 지점에서 수행할 수 있다.
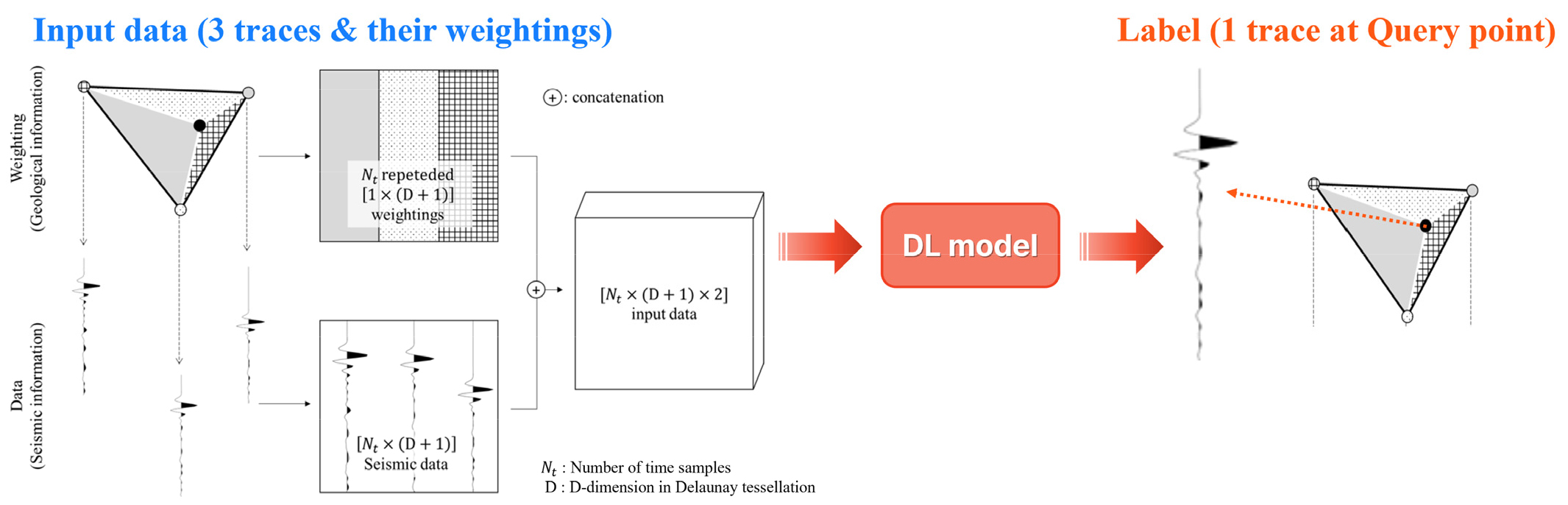
Fig. 7
Schematic diagram illustrating the construction of input data and label data for a given query point (modified from Yeeh, 2024). A U-Net architecture is used as the deep learning (DL) model.
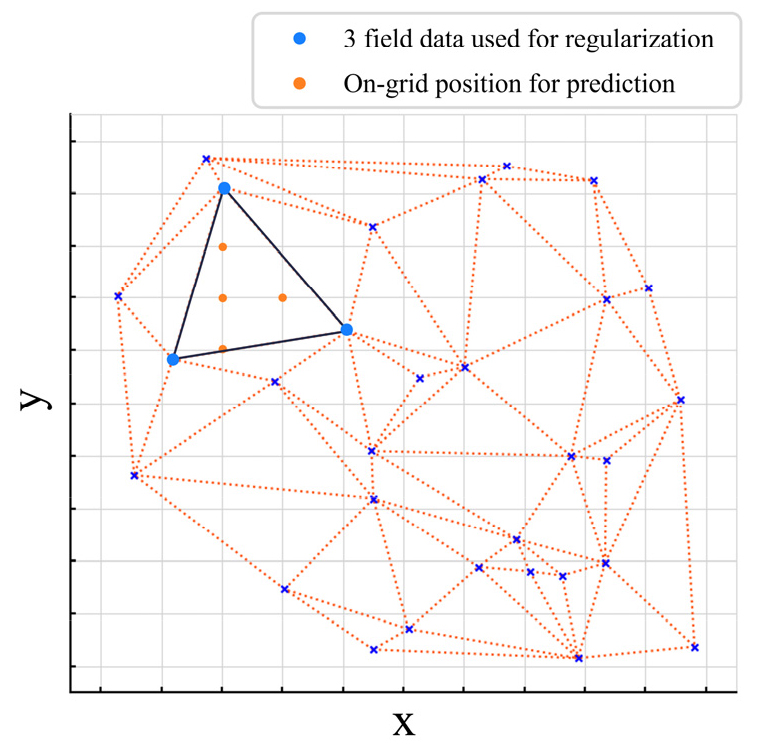
Fig. 8
Conceptual diagram showing how regularization is performed using the trained DL model. First, field data are triangulated using Delaunay tessellation. Then, three input traces at the vertices of a triangle (blue dots) are used to predict traces at grid locations inside the triangle (orange dots).
포항 현장 자료를 활용한 학습 자료 구성 및 학습
Yeeh (2024)의 트레이스 정규화 방법은 현장자료로부터 학습자료를 구성하므로 학습자료를 합리적으로 잘 구성해야만 좋은 예측성능을 보이는 딥러닝 모델을 얻을 수 있다. 이 연구에서는 포항 현장 자료 정규화를 위한 학습자료 구성을 위해 다음과 같은 과정을 수행하였다. 먼저, 현장에서 취득된 자료를 공통 수신기 모음 자료로 정렬하였다. 제안된 방법은 본래 해양 탄성파 탐사에서 주로 사용되는 송수신기인 에어건과 스트리머(streamer)로 취득된 자료를 대상으로 개발되었다. 따라서 하나의 송신원에 대해 많은 수신기를 가지므로 공통 송신원 모음(CSG; Common Shot gather) 상에서 학습을 진행한다. 그러나 OBN으로 취득된 포항 현장 자료는 송신원의 수가 훨씬 많고 수신기의 수가 제한적이므로 공통 송신원 모음이 아닌 공통 수신기 모음으로 자료를 정렬하였다.
다음으로 학습 자료 선정 전에 자료의 전처리 과정을 수행하였다. 우선 앞서 언급한 것과 같이 현장 자료에 존재하는 다양한 잡음의 영향을 줄이고 학습 성능을 개선하기 위해 주파수 대역 통과 필터링(bandpass filtering)을 수행하였다. 또한, 주변자료들을 이용한 내삽에서 가장 중요한 정보는 신호의 기록 시간이므로 수치적으로 계산한 직접파와 굴절파의 도달시간을 이용하여 자료 기록 시간의 정확성을 확인하였다. 포항 현장 자료를 인라인, 크로스라인 방향으로 도시한 결과 대체적으로 일관된 직접파와 굴절파의 기록시간을 보이는 인라인과는 달리 Fig. 9(a)와 같이 크로스라인 방향의 정적 효과(static shift)가 존재하였다. 정적 효과가 발생한 원인은 각 인라인 별 영점시간(zero time)이 정확히 맞지 않았기 때문으로 생각된다. 탐사 시 작성된 측선 발파 기록(log)에서 확인한 탐사 순서 정보와 인라인 측선 당 정적 효과의 정도를 비교한 결과, 탐사 순서가 후반부일수록 정적 효과가 크게 나타났으며 이로 인해 실제 도달 시각보다 늦게 기록된 것을 확인하였다. 이러한 정적 효과를 가진 자료를 학습이나 예측에 이용하면 정규화 성능에 치명적인 영향을 미칠 수 있다. 따라서 알려진 수심 및 송수신기에 대한 사전정보를 이용해 거리에 따른 직접파와 굴절파의 도달 시각을 계산하여 Fig. 9(b)와 같이 정적효과 보정을 수행하였다. 여기서 송수신기의 수평 거리는 탐사 시 기록된 송수신 배열로 계산하였으며, 수직 거리는 에어건의 위치(대략 수심 5 m)와 해저면 수심(약 16 m)을 고려한 11 m로, 해수층과 지층의 P파 전달 속도는 각각 1500 m/s와 1680 m/s를 사용하였다. 지층의 P파 전달 속도는 포항 영일만의 표층 퇴적물이 사질 퇴적물임을 보고한 Lee et al. (2023)과 사질 퇴적물의 속도 범위를 제시한 Seo and Kim (2000)의 결과를 참고하여 해당 범위 내의 여러 값을 대입한 후 현장 자료에 가장 적합한 값을 선택하였다. 또한 학습에 사용할 트레이스는 이산화탄소 주입층의 심도와 선행 연구(Shinn et al., 2018)에서 분석된 속도 구조를 고려하여 신호가 거의 없는 후기 시간대 자료를 제외하고 관심 지역이 충분히 포함될 수 있도록 1600개의 시간 샘플인 약 1.56 sec를 사용하였다.
이런 전처리 과정을 마친 자료로부터 학습자료를 선정하였다. 각 노드 별로 Fig. 3에 나타낸 송신 위치에서 발파된 자료들로 취합된 트레이스들 중 앞서 기술한 방법으로 4점을 선정하여 삼각형의 꼭짓점에 해당되는 3개의 트레이스가 입력자료로, 이 3개의 트레이스로 이루어진 삼각형 안에 존재하는 하나의 트레이스가 정답자료로 사용되었다. 여기서 R-value는 각 송신원 사이의 거리 및 4점을 선정하였을 때 생성되는 중심 좌표의 다양성을 고려하여 70 m로 설정하였다. 학습에 사용한 노드는 분석한 38개 노드 중 감도가 약하거나 잡음 수준이 높은 특성을 보이는 3개 노드를 제외한 35개 노드이다. 한편, 자료 분석 결과 수신 노드 직 상부 근처의 근거리 오프셋(near offset)에서 발파되어 기록된 탄성파 자료의 경우 노드의 최대 수음 가능 진폭을 넘어 트레이스의 절단(truncation)이 발생한 것을 확인할 수 있었다. 이와 더불어 근거리 오프셋에서 나타나는 강한 Scholte wave 역시 딥러닝 모델의 학습 성능을 저하시킬 가능성이 있으므로 이를 고려하여 수신 노드와의 거리가 100 m 이내에 있는 송신원에 의해 취득된 트레이스는 학습에서 제외하였다.
입력-정답 자료쌍 생성을 위한 변수를 선택한 후, 각 노드에서 10,000쌍씩 총 350,000 (=35×10,000)쌍의 학습자료를 생성하였다. Fig. 10(a)에 이렇게 생성된 학습자료의 중심 좌표 3개 중 작은 순으로 선택한 2개를 평면상에 도시하여 얻은 2차원 도수분포도를 히트맵(Heatmap)으로 나타내었으며, 특정 지점에 자료가 집중됨을 확인하였다. 또한 식 (1)에서 알 수 있듯, 세 중심 좌표의 합은 1이므로 이 중 두 개만을 도시하여도 전체 중심 좌표의 분포를 확인할 수 있다. 이처럼 중심 좌표가 고르게 분포하지 않는 이유는 이 자료의 송신 배열이 완전히 무작위적이지 않고 전체적으로 일정한 규칙하에 배열된 가운데 일부 틀어짐이 발생한 형태이기 때문이다(Fig. 3). 이렇게 학습자료의 분포가 특정 값에 편중되면 예측 성능이 정규화 하는 위치에 따라 많은 격차를 보이는 학습모델을 얻을 가능성이 높아진다. 따라서 이를 막기 위하여 각 노드 자료에서 중심좌표의 값에 관계없이 무작위로 뽑았던 전략을 수정하여 특정 값을 갖는 자료의 수를 지정해서 자료쌍을 선택하도록 하였다. 즉, 도수분포도 상에서 가능한 한 고른 분포를 갖도록 자료쌍의 구성을 조정하였다. 이를 위해 먼저 도수분포도의 구간 폭(bin width)을 결정하였다. 현장 자료의 송신원 배열 형태로부터 생성 가능한 중심 좌표를 분석한 결과, 4개의 송신원 중 하나의 위치가 1 m 내에서 변화할 때 중심 좌표의 최대 변화량이 약 0.04였으므로 도수분포도의 구간 폭을 0.04로 도시하였다(Fig. 10(b)). 다음으로 이 도수분포도 상의 단위 격자에 최대 160개의 자료쌍이 들어가도록 선택하여 총 9,878쌍을 선택하였다(Fig. 10(c)). 그림에서 볼 수 있는 것처럼 이 전략을 통해서 다양한 입력-정답 자료의 위치 조합이 골고루 선택된 것을 확인할 수 있고, 여기서 사용한 9,878 쌍은 학습 자료의 다양성과 패치화 이후 모델에서 학습 가능한 자료의 양을 고려하여 총 10,000쌍 내외가 되도록 경험적으로 선택한 값이다.
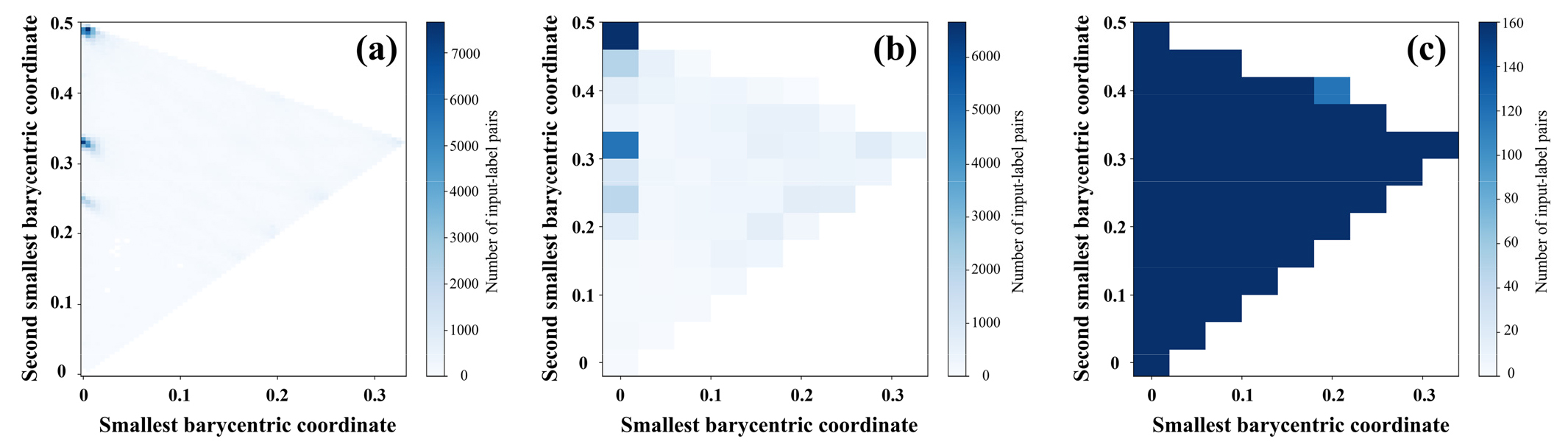
Fig. 10
Distribution of the smallest and second-smallest barycentric coordinates (area-based weighting) of input–label pairs: two-dimensional histograms with bin widths of 0.005 (a) and 0.04 (b) for randomly selected pairs, and a bin width of 0.04 (c) for pairs selected using a specific strategy (up to 160 pairs per grid).
딥러닝 모델 학습을 위하여서는 앞서 설명한 대로 4개의 트레이스 쌍이 그대로 들어가는 것이 아닌 256개의 시간 샘플을 갖는 43개의 패치로 분할하여 사용된다. 이때, 신호가 없는 직접파 도달 이전인 초기 시간대의 패치와 신호의 세기가 약해져 잡음과 거의 구분이 안되는 후기 시간대의 패치를 학습시키는 것은 학습을 방해할 수 있으므로 학습 자료에서 제외하였다. 선별이 완료된 패치는 총 401,957개로, 이 중 80%는 훈련(train) 자료로, 20%는 검증(validation) 자료로 사용하였다. 또한 안정적인 학습을 위해 학습 자료는 패치화 된 세 입력 자료를 기준으로 최대 절댓값(MaxAbs) 정규화 방법을 이용해 정규화 하여 사용하였다.
Fig. 11에 학습에 사용한 딥러닝 모델 구조를 나타내었다. 연결성 향상을 위해 Yeeh (2024)가 사용한 U-Net 원본 모델에서 3×3이었던 커널(kernel) 크기를 5×3으로 변경하였다. 손실 함수(loss function)는 평균 절대 오차(mean absolute error)로, 학습률(learning rate)은 5.0×10-4으로 설정하였다. 또한 과적합을 방지하기 위해 조기 종료(early stopping) 기법을 적용하여 검증 손실(validation loss)이 20회 이상 개선되지 않을 경우 학습을 중단하도록 설정하였다. 최종 모델은 총 252회까지 학습되었으며 그 중 검증 손실이 가장 낮은 232번째 모델이 최적 모델로 저장되었다.
포항 현장 자료 정규화 결과 및 고찰
앞서 학습된 딥러닝 모델을 이용해 포항 현장자료에 대한 정규화를 수행하기 위해 먼저 입력자료를 구성하였다. 이 연구에서는 자료들의 신호 간 연결성을 잘 보여주어 추후의 정규화 된 자료에 적용될 수 있는 자료처리를 효과적으로 수행할 수 있도록 정규화 할 송신원의 위치를 10 m 간격의 94×115 (Fig. 12(a)) 크기로 설정하였다. 다만, 이 방법은 삼각형을 이루는 주변의 세 점의 자료를 이용하여 그 내부의 위치의 자료를 생성하므로 정규화 할 위치는 기존 송신원 배열 내부에 위치하여야 한다. 현장자료의 송신원 배열은 델로네이 공간분할을 통해 Fig. 12(b)와 같이 분할되었으며, 각각의 정규화 위치에 대한 중심 좌표를 계산하여 트레이스와 함께 예측 입력자료로 사용하였다. 예측은 앞서 학습에서 기술하였던 자료의 품질이 비교적 양호한 35개 노드 전 자료에 대해 수행하였다.
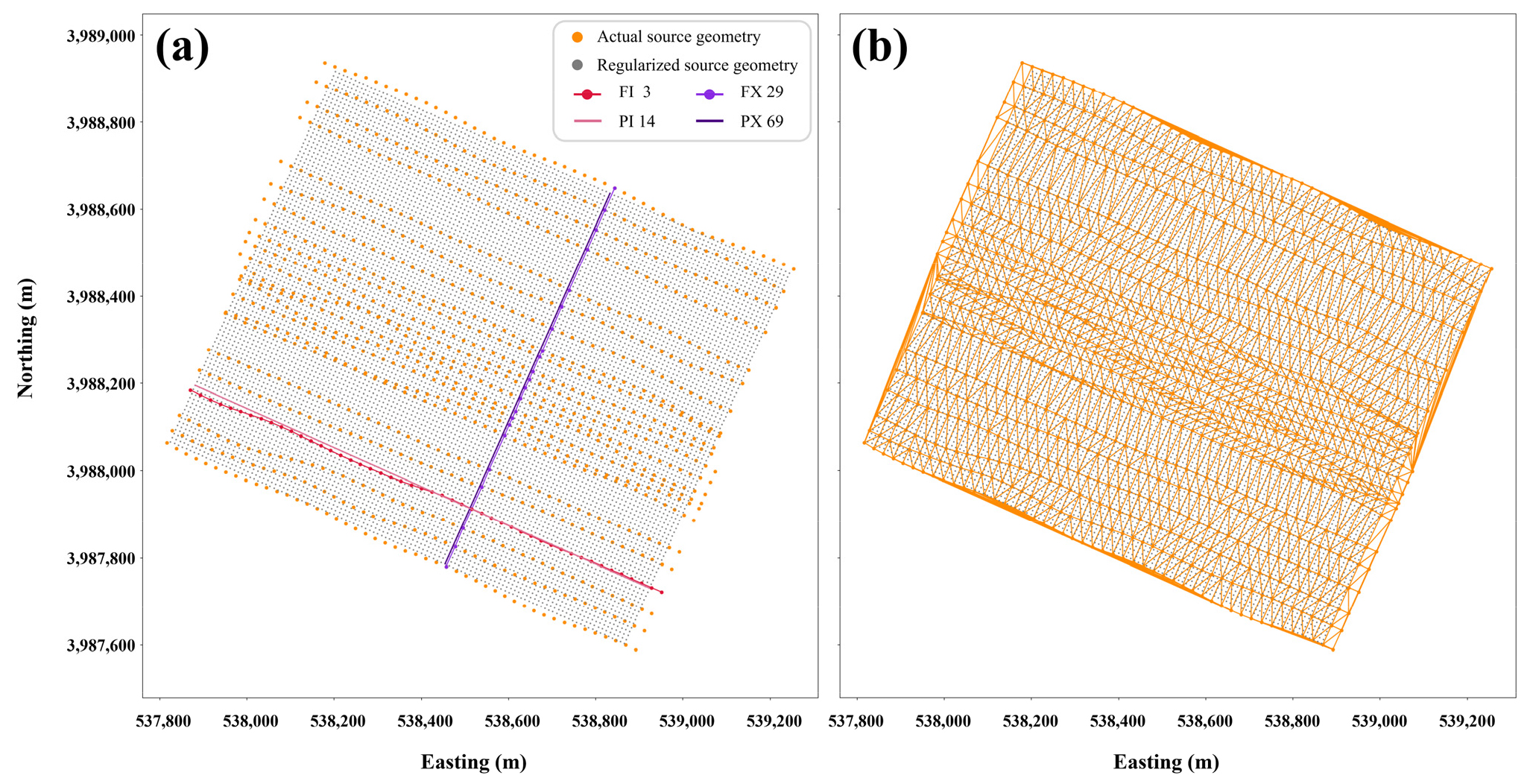
Fig. 12
Source geometry and results of Delaunay tessellation using source positions. (a) Actual source and regularized grids geometries and (b) results of Delaunay tessellation using the actual source geometry are superimposed on figure (a). The prefixes PI and PX in the survey line numbers denote prediction Inline and prediction Xline, respectively.
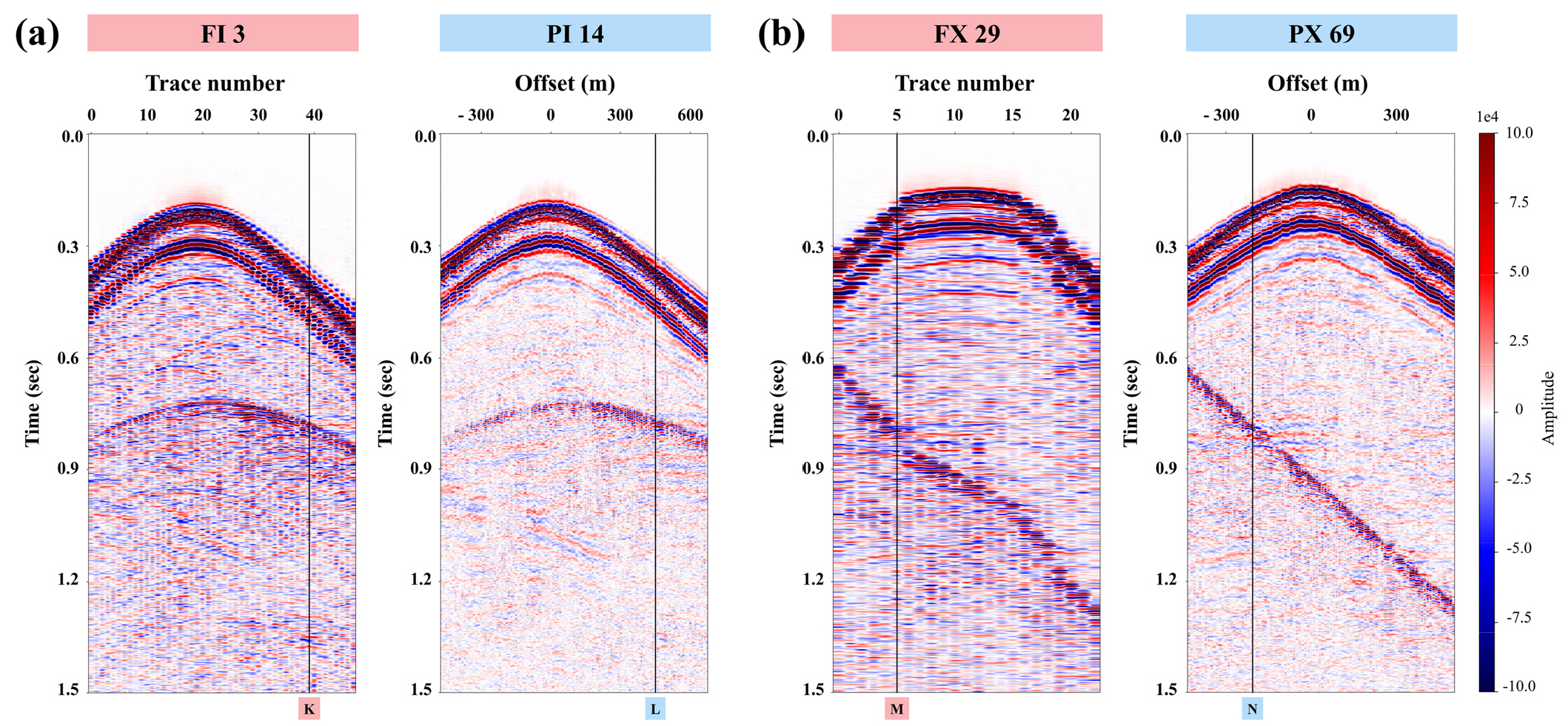
Fig. 13에 OBN 12번에서 취득된 현장자료와 딥러닝 모델로 예측한 정규화 결과를 시간 단면(time slice) 0.831 sec에 대해 도시하였다. 모든 자료들은 시각화의 편의성을 위해 송신원 위치에 도시하였다. Fig. 13(a)에서 볼 수 있는 바와 같이 희소하게 산재하였던 기존의 현장 자료가 Fig. 13(b)와 같이 10 m의 훨씬 조밀한 간격을 갖는 정규화 된 위치로 예측되어 현장 자료에서 잘 관찰되지 않던 탄성파의 전파 거동 패턴이 예측 결과에서 명확하게 나타남을 확인하였다. 이러한 시간 단면으로부터 탄성파의 진행 양상을 스냅샷(snap shot)의 형태로 쉽게 확인할 수 있으며, 특히 Fig. 13(b)의 하부에서 강하게 나타나는 반사파 패턴은 지리적으로 단면의 하부 쪽에 위치하는 방파제로부터 기인하는 반사파 라는 것을 바로 확인할 수 있게 한다.
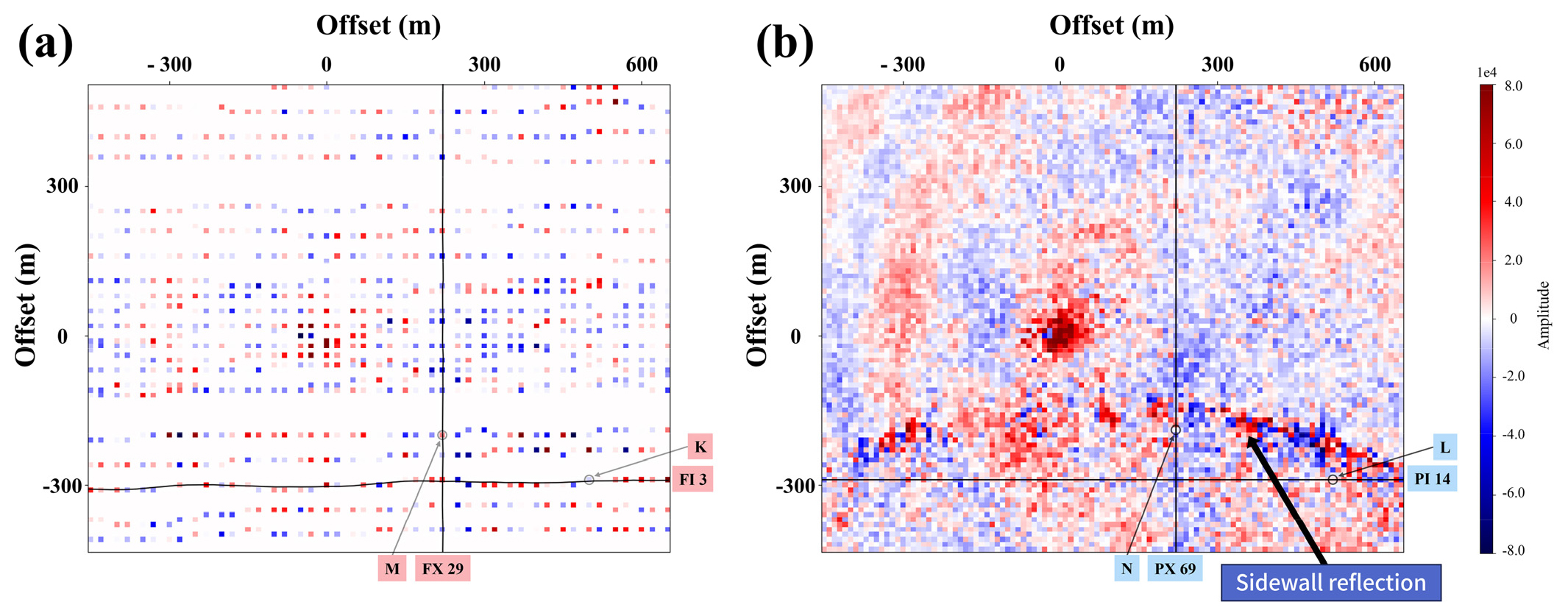
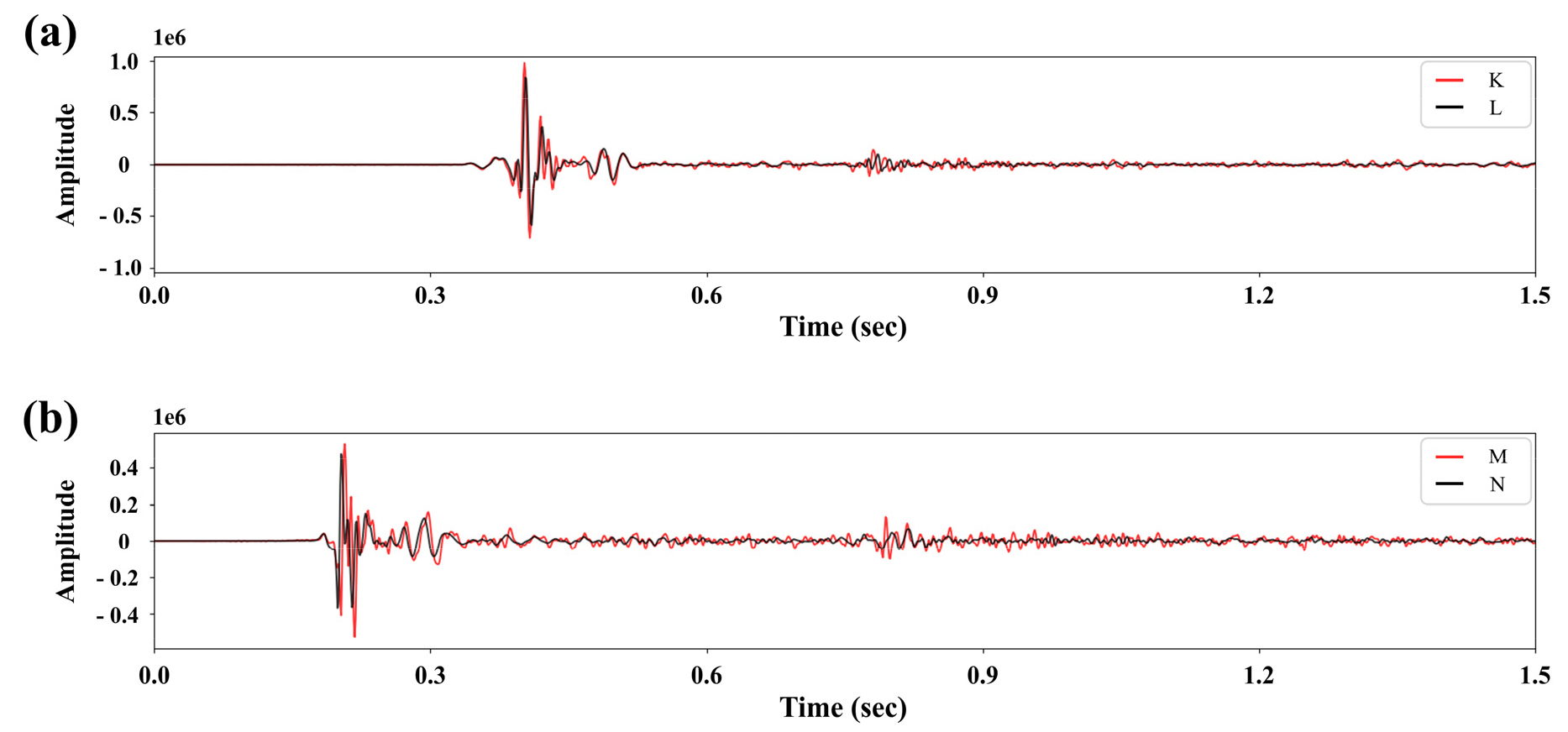
다음으로 원자료인 현장 자료와 10 m의 간격으로 정규화 된 예측 결과를 인라인과 크로스라인에서 비교해보았다(Fig. 14). Fig. 12(a)의 송신원의 위치도와 Fig. 13의 시간 단면에 표기한 것과 같이 FI (Field Inline) 3번과 가장 가까운 PI (Prediction Inline) 14번, FX (Field Xline) 29번과 가장 가까운 PX (Prediction Xline) 69번을 각각 비교하였다. 인라인의 경우 Fig. 12(a)에서 볼 수 있듯이 라인이 약간 틀어진 것 외에는 25 m 간격으로 비교적 일정하게 취득되었으므로 FI 3과 PI 14에서 전체적인 형태가 비슷하게 나타났다. 그러나 크로스라인의 경우 현장 자료의 취득 간격이 불규칙하여 0.6초부터 1.3초 사이에 나타나는 방파제 반사파가 FX 29에서는 휘어져 있는 것을 확인할 수 있다. 이와 달리 정규화 이후인 PX 69에서는 방파제 반사파가 직선으로 나타나 이후 자료처리를 통해 이를 효과적으로 제거할 수 있을 것으로 보인다. 또한 인라인과 크로스라인 모두에서 현장 자료에 비해 예측 결과의 진폭이 다소 작게 나타나 에너지가 감소한 것을 확인할 수 있는데, 이는 전체적으로 무작위 잡음이 덜 예측되는 경향으로 인한 것이며 0.7초–0.9초에 나타나는 이산화탄소 주입대상 지층 심도에서의 신호의 연결성은 향상된 것을 볼 수 있다. 더 자세한 분석을 위하여 Fig. 15에 개별 트레이스의 현장 자료와 예측 결과를 함께 나타내었다. 각 트레이스의 모음 상에서의 위치는 Fig. 14에서 확인할 수 있다. 앞서 언급한 것과 같이 예측 결과가 현장 자료의 진폭보다 다소 작은 것을 볼 수 있으며 이는 초기 시간대의 강한 직접파에서 더욱 두드러지게 나타난다. 직접파의 경우는 일반적으로 딥러닝 모델을 이용한 내삽에서 상대적으로 큰 에너지를 갖는 신호의 에너지 복원율에서 다소 손실(leakage)이 발생하는 현상도 영향을 미친 것으로 보인다(Wang et al., 2019). 그러나 후기 시간에 나타나는 신호 외의 무작위 잡음들은 전체적으로 억제된 것을 볼 수 있으며 이 결과가 Fig. 14에서 원자료에 비해 정규화된 자료의 에너지가 감소한 것처럼 보이는 원인이라는 것을 다시 한번 확인할 수 있다. 한편, Fig. 15(a)에서와 달리 Fig. 15(b)의 원자료와 예측 결과인 두 트레이스는 약간의 위상 차이를 보이는데, 그 이유는 현장 자료와 가장 가까이 있는 예측 위치를 선정하여 비교하였지만 이 둘이 완전히 같은 위치에 있는 것은 아니기 때문이다. Fig. 15(a)의 K와 L은 약 1 m 거리인 데 반하여, Fig. 15(b)의 M과 N은 약 4 m 가량 떨어져 있기 때문에 이 영향으로 생각된다.
토 의
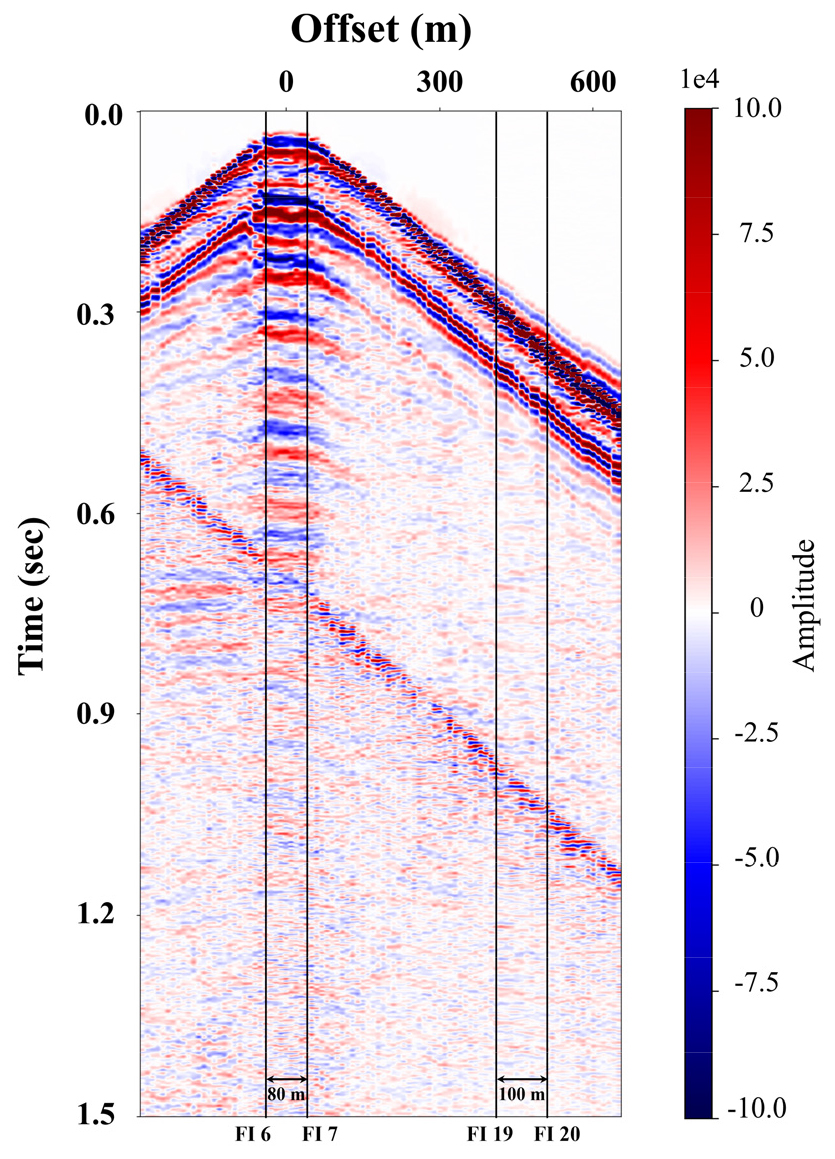
딥러닝 기반 3차원 정규화 기법을 모든 수신 노드 자료에 적용한 결과, 대다수 구간에서 우수한 정확도로 정규화 됨을 확인하였다. 정규화 된 트레이스들은 신호의 에너지의 약간의 손실을 보이기는 했지만 잡음이 억제되어 신호 간 연결성은 향상된 모습을 보였다. 그러나 Fig. 16에 나타낸 33번 노드의 인라인 77번(PI 77) 자료와 같이 특정 수신 노드(9, 17, 25, 33번)에서는 근거리 오프셋 부근이 정확하게 영상화 되지 않았다. 해당 노드들은 Fig. 3에서 볼 수 있듯이 모두 직 상부 주변에 송신원이 존재하지 않는 곳에 위치한다. OBN에서 얻어진 자료의 특성상 수신기 근거리 오프셋 구간은 도달 시각이 비선형적으로 변하는 곳이다. 이 논문에서 적용한 정규화 기법은 주변의 세 트레이스만을 사용하여 정규화 될 위치의 트레이스를 예측하기 때문에 곡률이 큰 구간에 송신원이 전혀 존재하지 않을 경우 이와 같은 문제가 발생할 수 있다. 그러나 입력 자료 사이에 큰 거리 차이(big gap)가 존재하더라도 선형적인 변화를 갖는 구간은 비교적 잘 예측될 수 있다. Fig. 16에서 보면 80 m 거리를 갖는 FI 6과 FI 7 사이는 비선형적인 변화를 보이는 구간으로 실제 예측되어야 한다고 생각되는 자료와는 다소 차이 나는 결과를 보여준 데 비해 FI 19와 FI 20 사이의 100 m 거리 구간은 굴절파와 직접파, 방파제 반사파 모두 잘 연결된 것을 볼 수 있다. 이처럼 탄성파 신호들의 곡률 변화를 보이는 부분의 자료부족으로 인한 예측의 불확실성에 대해서는 추가적인 연구가 필요할 것으로 생각된다.
이 연구에서는 현장자료에 적합한 R-value를 설정하기 위해 송신원 간 거리와 학습자료의 중심 좌표의 다양성을 고려하였다. 이를 위해 Yeeh (2024)에서 제안한 방식과 같이 현장 자료의 위치에 델로네이 공간분할을 적용하여 얻은 simplex의 모든 변의 길이 분포를 분석하였다. 분석 결과 입력자료들의 범위는 5~111 m로, 평균적으로 46 m이다. 이를 바탕으로 111 m 의 자료가 학습자료에 충분히 포함될 수 있도록 R-value를 70 m로 하여, 140 m의 지름을 갖는 원 안에서 학습자료가 생성될 수 있도록 하였다.
이 기술은 현재 송신원 배열 내부에 정규화 지점을 설정하여 송신원 사이를 정규화하는 데 활용되었으나, 송신원-수신기 간 상호성을 고려하면 동일한 방식으로 수신 노드 간 정규화에도 적용할 수 있어 수신 노드의 수를 확장할 수 있다. OBN 자료의 경우 송신원보다 수신기의 수가 더 적으므로 이 방법을 사용할 수 있다면 큰 도움이 될 것으로 생각된다. 다만 수신 노드 사이를 정규화하기 위해서는 수신기 노드 간의 자료 상태가 비슷해야 하는데, 이 현장 자료의 경우는 노드 별로 자료의 상태가 달라 적용하기 어려웠다. 따라서 추후 각기 다른 특성을 갖는 자료들을 비슷하게 만드는 정합필터(matching filter)와 같은 자료처리 기술들에 대한 연구가 적용될 수 있다면 수신 노드에 대한 정규화도 시도해 볼 수 있으리라 생각된다.
결 론
이 연구에서는 Yeeh (2024)에 의해 개발된 딥러닝 기반 3차원 트레이스 정규화 기법을 포항 영일만 OBN 현장 자료에 적용하였다. 기존에 에어건과 스트리머를 이용해 취득된 자료를 대상으로 개발된 기법을 OBN으로 취득된 자료에 알맞게 적용하기 위해 공통 송신기 모음 대신 공통 수신기 모음으로 자료를 정렬한 후 사용하였다. 또한, 자료의 정규화는 전처리가 전혀 안 된 중합전(pre-stack)의 원자료에 대해 수행되기 때문에 잡음의 영향을 줄이기 위해 주파수 대역 필터링을 수행하고 내삽의 가장 중요한 정보인 도착 시간 정보를 정확히 하기 위한 정적 효과 보정을 수행하였다. 특히 이 정규화 방법은 주변의 세 개의 트레이스에서의 입력자료를 이용하여 정규화 될 위치의 트레이스를 예측해 내는 방법으로 정적 효과 보정이 딥러닝 모델의 학습 성능에 가장 큰 영향을 준다. 따라서, 주어진 정보들을 최대한 활용해 직접파 및 굴절파의 도달 시각을 계산하여 모든 자료들의 정적효과를 최대한 합리적으로 보정하였다. 다른 자료처리의 경우와 마찬가지로 탐사 과정에서 송신기가 발파되는 시간인 영점시간을 정확하게 맞추어 취득하는 것이 무엇보다 중요하지만, 학습에 들어가기 전에 자료들이 정적효과 보정이 필요한 지 여부에 대한 확인이 반드시 필요하다는 것을 알 수 있었다. 한편, 정규화 수행 시 임의의 위치에 존재하는 트레이스도 합리적으로 예측하는 딥러닝 모델 생성을 위해서는 학습 자료로 사용되는 입력 트레이스들과 정답자료로 사용되는 트레이스 사이의 위치 관계로 나타나는 중심 좌표를 고르게 분포하도록 구성하는 게 중요하다. 따라서 이 연구에서는, 학습 자료를 구성하는 중심 좌표가 편중되지 않도록 각 노드에서 학습자료를 뽑을 때 이 조건을 만족하도록 학습 자료를 선별하여 구성하였다. 또한, 패치화되어 들어가는 트레이스들도 잡음만 섞인 패치는 제외하여 학습 성능을 향상시켰다.
학습시킨 딥러닝 모델을 비교적 신호의 질이 좋은 35개의 모든 수신 노드에서 얻어진 자료에 적용하여 원래 간격인 25 m 내지 50 m보다 더 조밀한 10 m의 송신기 간격을 갖는 자료들로 정규화 시켰다. 예측된 결과는 비록 상대적으로 큰 에너지를 갖는 구간에서 기존 원자료보다 에너지 복원율에 일정 부분 손실을 보였으나 주 신호들이 거의 잘 예측되었고, 후기 시간대에 나타나는 무작위 잡음이 억제된 것을 확인하였다. 정규화된 공통 수신기 모음 시간 단면을 확인한 결과 주 신호들이 연결성 있게 잘 예측되어 원자료 만으로는 파악하기 힘들었던 탄성파의 공간적인 거동들도 잘 파악할 수 있었다.
탐사 현장에서 자주 발생하는 페더링(feathering)이나 자료결손 등으로 인해 불규칙하게 취득된 탄성파 자료는 이후의 자료 처리 기법 적용과 자료의 품질을 높이기 위해 정규화 되어야 하기 때문에 최근의 머신러닝 기술을 이용한 정규화에 대한 연구도 많은 관심을 받고 있다. 이 연구에서 포항 현장자료에 대해 적용성을 보여준 트레이스 기반 3차원 정규화 방법은 현장자료 자체를 이용한 학습이 가능하고 불규칙하게 위치한 3차원 탐사자료에 자유롭게 적용시킬 수 있다는 강점을 가지고 있어 추후에도 많은 활용이 가능하리라 생각된다.
