

서 론
탄성파 자료처리는 취득한 탄성파 자료를 분석하여 지구 내부의 구조와 특성을 파악하는 기술로, 자료 수집, 전처리, 속도 분석, 신호 처리, 이미지화 단계로 분류할 수 있다(Yilmaz, 2001). 전처리 단계에서는 잡음 제거, 정규화, 필터링 등을 수행하여 자료를 분석하기 위한 적합한 형태로 변형한다. 속도 분석 및 신호 처리 단계에서는 스태킹, 디컨볼루션, 필터링 등의 기법을 사용하여 지하 매질의 속도 구조를 파악하고, 최종적으로 구조보정된 이미지를 통해 지질학적 구조를 규명한다. 각 자료처리 단계에서는 독립적인 연산이 요구되며, 특히 3차원 자료를 처리할 때는 연산량이 방대해진다. 방대한 연산량은 탄성파 자료처리의 주요 도전 과제 중 하나이며, 보다 효율적인 자료처리 방법이 지속적으로 요구되고 있다(Hegna et al., 2019; Helbig and Thomsen, 2005).
이러한 도전 과제를 해결하기 위해 도입된 머신러닝(machine learning) 기술은 탄성파 자료처리 분야에서 중요한 도구로 자리 잡고 있다(Anjom et al., 2020). 잡음 제거 영역에서는 합성곱 신경망(Convolutional Neural Network, CNN), 생성적 적대 신경망(Generative Adversarial Network, GAN), 오토인코더 모델을 이용하여 랜덤 잡음 제거, 다중 반사파 제거, 그라운드 롤 감쇠 등이 수행되었다.(Wu et al., 2019a; Yu et al., 2019; Wang and Nealon, 2019). 속도 모델 구축(velocity model building)에서는 원시 자료를 입력받아 속도 모델을 출력하는 방식으로 주로 CNN 및 다층 퍼셉트론(multi-layer perceptron) 모델이 사용되며, 정답 자료 부족 문제 해결을 위해 GAN도 사용되고 있다(Araya-Polo et al., 2017; Yang and Ma, 2019; Kazei et al., 2020). 최근에는 물리 기반 신경망(physics-informed neural network)을 활용하여 물리적 제약을 강화한 모델도 연구되고 있다(Raissi et al., 2019; Xu et al., 2019). 초동 발췌(first-break picking)에서는 주로 CNN 모델이 사용되었으며(Wu et al., 2019b), 전통적인 초동 발췌 기법보다 우수한 결과를 보여주었지만 신호 대 잡음비가 낮은 자료에서는 한계가 존재했다(Cova et al., 2020). 머신러닝을 적용한 기존 자료처리 연구 대부분은 특정 탄성파 처리 작업에만 집중되어 있어, 자료에 내재된 유사한 특징과 구조를 충분히 활용하지 못하는 한계가 있다. 이는 다양한 자료 간의 공통적인 패턴을 발견하고 일반화된 솔루션을 개발하는 데 어려움을 초래한다. 따라서, 이러한 한계를 극복하기 위해서는 다양한 자료와 처리 작업을 통합적으로 다루는 접근 방식이 요구된다.
최근 자연어 처리(natural language processing)와 컴퓨터 비전(computer vision) 등 다양한 분야에서 트랜스포머(transformer) 모델이 큰 주목을 받고 있다. 트랜스포머는 ‘Attention is All You Need’라는 논문에서 처음 제안된 모델로, 시퀀스 자료에서 중요한 정보를 효과적으로 추출할 수 있는 어텐션 메커니즘(attention mechanism)을 사용한다(Vaswani et al., 2017). 이 모델은 입력 시퀀스의 모든 위치 간의 관계를 한 번에 고려할 수 있어, 기존의 순환 신경망(recurrent neural network)보다 더 높은 효율성과 성능을 제공한다. BERT (Bidirectional Encoder Representations from Transformers)는 트랜스포머 구조의 인코더를 기반으로 한 모델로, 양방향에서 자료를 처리하여 문맥을 깊이 있게 이해할 수 있는 능력을 갖추고 있으며, 사전훈련(pretraining)과 미세조정(finetuning) 과정을 거쳐 다양한 자연어 처리 작업을 수행한다(Devlin et al., 2019). Harsuko and Alkhalifah (2022)는 이러한 BERT 모델의 특성을 활용하여, 특정 작업에만 적용되던 방식이 아닌 통합된 형태의 탄성파 자료처리가 가능한 기법을 제안하였다. 사전학습 단계에서는 자연어 처리에서 BERT가 토큰 단위로 학습되는 것과 달리, 각 수신기의 시계열 자료가 토큰으로 입력되었다. 이를 통해 탄성파 자료의 주요 특징을 저장한 사전학습 모델로부터 잡음 제거, 속도 추정, 초동 발췌 등의 다양한 자료처리 작업을 적은 양의 추가 훈련을 통해 수행했다.
본 연구에서는 BERT 기반의 사전학습을 위해 송신원 모음에서 수신기별 시계열 자료(이하 ‘수신기 배열’)와 동일 시간에 기록된 수신기 신호(이하 ‘시간 배열’)를 입력 자료로 활용하는 방법을 비교하고자 한다. 단순 속도 모델에서 생성한 단일 합성 송신원 모음 자료를 이용하여 각 배열로 사전학습 모델을 훈련하고, 이를 미세조정하여 잡음 제거, 속도 추정, 단층 확인 등의 자료처리에 적용하여 결과를 비교하였다.
BERT 기반 사전학습을 이용한 탄성파 자료처리
BERT 기반 사전학습 네트워크 구조
본 연구에서 이용한 BERT 기반 송신원 모음 자료 사전학습 네트워크 구조는 Harsuko and Alkhalifah (2022)와 유사하며 Fig. 1과 같다.
자연어 처리 분야에서는 일반적으로 텍스트를 단어 또는 토큰으로 분할하고, 토큰, 세그먼트, 위치 인코딩(positional encoding)을 수행하여 입력 자료로 사용한다. 그러나, 송신원 모음 자료를 사용할 때는 토큰 및 세그먼트 인코딩 작업이 불필요하기 때문에 Fig. 1과 같이 마스킹과 위치 인코딩만을 수행한다. 마스킹(masking)은 입력 자료에서 일부분을 의도적으로 숨기는 작업으로, 수신기 또는 시간 배열 무작위로 선택하여 임의의 값으로 변경하거나 주변 배열로 대체하는 과정이다. 위치 인코딩은 시퀀스 내 각 요소의 위치 정보를 모델에 제공하는 방식으로, 사인과 코사인 함수의 주기적인 패턴을 사용하여 각 위치에 고유한 값을 할당하여 입력 시퀀스의 각 요소가 시퀀스 내에서 어느 위치에 있는지를 학습하게 한다.
마스킹과 위치 인코딩이 완료된 자료는 임베딩 블록을 통해 숨겨진 차원으로 변환된다. 임베딩된 자료는 여러 개의 인코더 블록을 통과하게 된다. 각 인코더 블록은 Fig. 1과 같이 멀티-헤드 어텐션 레이어(multi-headed attention layer), 피드-포워드 레이어(feed-forward layer), 잔차 연결(residual connection), 그리고 레이어 정규화(layer normalization)로 구성된다. 레이어 정규화는 각 샘플의 레이어 출력을 독립적으로 정규화하여, 입력 값의 평균과 분산을 계산한 후 이를 통해 정규화된 값을 학습 가능한 파라미터를 사용해 스케일링과 시프팅하는 방식으로 이루어진다. 멀티-헤드 어텐션 레이어에서는 임베딩된 자료를 쿼리, 키, 값으로 변환하여 어텐션 연산을 수행한다. 이 연산은 각 입력 자료가 다른 모든 입력 자료와의 관계를 학습하여 가중치를 적용하는 방식이다. 피드-포워드 레이어는 두 개의 층으로 이루어진 신경망이며, 마지막 인코더 블록의 출력은 예측 헤드(prediction head)로 전달된다. 예측 헤드는 숨겨진 차원의 자료를 원래 입력 차원으로 다시 변환하여 최종 출력 자료를 생성하고, 이를 마스킹되지 않은 송신원 모음 자료와 비교하여 L2 손실을 계산하여 누락된 정보를 복원하며 자료의 주요 특징들을 사전학습 모델에 저장한다.
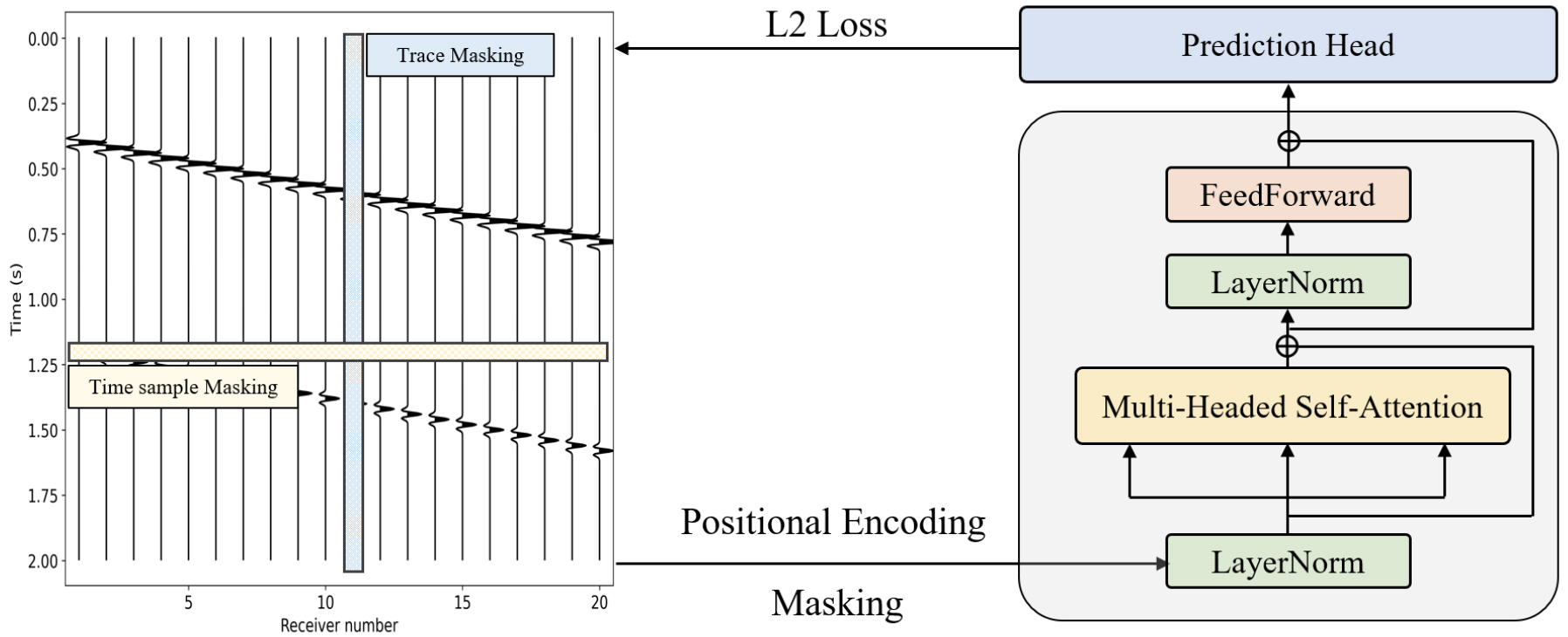
Fig. 1.
Architecture of the BERT-based pretraining network for seismic data. The left panel shows trace masking (blue bar) and time sample masking (yellow bar) applied to the seismic data. The right panel depicts the transformer encoder with multi-headed self-attention, layer normalization, feedforward layers, and positional encoding, which is used to compute the L2 loss for pretraining.
합성 송신원 모음을 이용한 사전학습
BERT 기반 사전학습 네트워크를 실험하기 위해 단층을 포함하는 단순 속도 모델에서 합성 송신원 모음 자료를 생성하였다. 총 1,500개의 속도 모델을 사용했으며 4층에서 7층 사이의 지층을 포함한다(Fig. 2). 이 중 80%인 1,200개를 훈련 자료로 사용하였고, 나머지 20%인 300개를 시험 자료로 이용하였다. 송신원 모음 생성을 위해 2차원 음향파 방정식을 엇격자(Staggered Grid)로 수치 모델링 했으며(Graves, 1996) PML (Perfectly Matched Layer) 경계 조건을 적용하여 원하지 않는 반사파를 제거했다(Komatitsch and Martin, 2007). 수치 모델링에 대한 세부 사항은 Table 1에 요약되어 있다.
실험을 위해 딥러닝 프레임워크로는 Pytorch를 사용하였고, BERT 모델을 구현하기 위해 Transformer 패키지를 활용하였다. BERTMINI 모델에 해당하는 하이퍼파라미터를 사용하였으며, 해당 모델은 L = 4 (어텐션 레이어), H = 256 (히든 레이어 차원), A = 4 (어텐션 헤드)를 갖추고 있다. 실행 과정은 StorSeismic의 깃허브를 참고하였다(Harsuko and Alkhalifah, 2022). 연산은 NVIDIA GeForce RTX 4090 GPU, 128 GB RAM, 그리고 13th Gen Intel Core i9-13900K 3.00 GHz Cpu를 탑재한 시스템에서 수행되었고, 효율적인 딥러닝 연산을 위해 CUDA가 사용되었다.
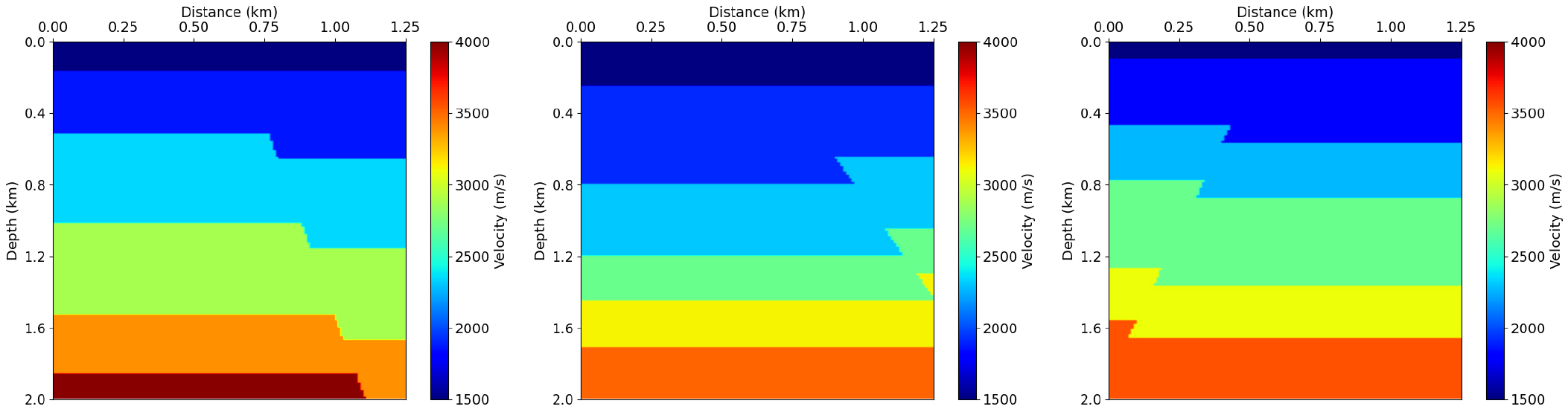
Table 1.
Parameters used for 2D numerical acoustic modelling.
생성된 송신원 모음의 크기는 수신기 118개와 시간 샘플 2000개였으나, 계산 효율을 높이기 위해 시간 축을 167개로 줄였다. 기존 시간 샘플 간격은 1 ms였으며, 리샘플링 후의 시간 샘플 간격은 약 12 ms이다. 축소된 시간 샘플에서도 실험에 필요한 신호들이 누락되지 않음을 확인하였다. 학습 자료의 수를 늘리기 위해, 각 송신원 모음 자료를 10배로 중복 생성하고, 시계열 자료를 위, 아래로 이동시키는 방식으로 자료를 추가했다. 사전학습 단계에서 BERT 모델의 입력 자료는 수신기 배열 자료의 경우 수신기 개수와 시간 축으로 이루어진 125 × 167이며, 출력 크기도 동일하다. 시간 배열 자료의 경우에는 이와 반대로 167 × 125로 구성된다. 전체 자료의 15%를 마스킹하였으며, 마스킹된 자료의 80%는 -1에서 1 사이의 값을 가지는 정규분포를 따르는 무작위 자료로 대체하고, 10%는 동일한 송신원 모음에서 다른 시계열 자료 또는 다른 시간 샘플을 복사하여 대체하였으며, 나머지 10%는 원래 자료를 유지하였다. 이러한 방법은 BERT의 마스킹 언어 모델링 기법(masked language modeling)을 응용한 것으로, 모델이 다양한 자료 복원 상황을 학습하도록 설계하였다(Devlin et al., 2019).
사전학습은 Fig. 1의 네트워크를 따라 마스킹된 입력 자료와 마스킹되지 않은 정답 자료의 차이를 줄여나가는 방식으로 학습이 진행된다. 이는 보간 작업과 유사하며, 학습을 통해 마스킹된 부분의 자료를 복원하는 과정이다. 사전학습에서는 Adam 최적화 알고리즘을 사용하였고, 학습률은 0.0005로 설정하였다. Fig. 3는 마스킹 적용 후의 송신원 모음, 복원된 결과, 마스킹 적용 전의 송신원 모음(정답 자료), 그리고 정답 자료와 복원된 결과의 차이를 보여준다. 비록 합성 자료에서의 결과이긴 하지만 수신기 배열 자료와 시간 배열 자료 모두에서 마스킹된 자료가 복원된 것을 확인할 수 있으며, 이는 송신원 자료의 특성을 잘 보존하고 있음을 의미한다.
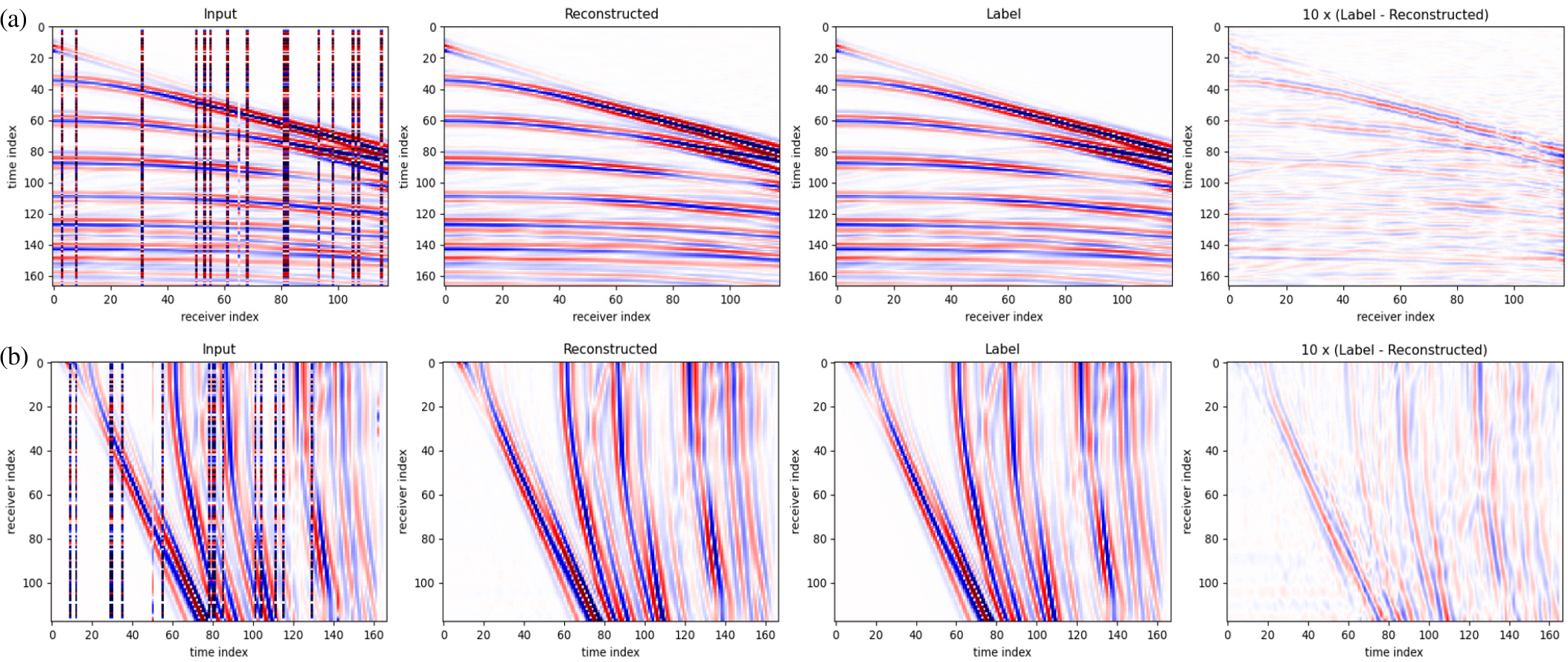
Fig. 3.
Comparison of masked and restored shot gather data for (a) receiver array and (b) time array. Each subfigure contains four images: masked shot gather, restored result, original shot gather (ground truth), and the difference between the ground truth and the restored result (difference scaled by 10× for clarity).
미세조정(잡음 제거, 속도 예측, 단층 확인)
자연어 처리 분야에서 BERT는 대규모 텍스트 코퍼스를 사용하여 사전학습되며, 그 후 특정 작업(예: 질문 응답, 문장 분류 등)에 맞춰 미세조정된다. 이 과정에서 모델은 사전학습 단계에서 학습한 언어 이해 능력을 바탕으로 새로운 작업에 최적화된다. 본 연구에서는 송신원 모음 자료를 사용하여 사전학습 된 모델을 다양한 탄성파 처리 작업에 맞춰 미세조정하고자 한다. 이러한 접근 방식의 장점은 각 작업을 독립적으로 처리하는 대신, 사전학습을 통해 얻은 정보를 공유함으로써 효율적으로 자료처리를 수행할 수 있다는 점이다(Harsuko and Alkhalifah, 2022). 사전학습 단계에서 모델은 수신기 배열과 시간 배열에 따른 일반적인 패턴과 특성을 학습하게 되며, 이를 바탕으로 특정 작업에 필요한 세부적인 조정만하면 된다. 본 실험에서는 사전학습된 모델을 미세조정하여 잡음 제거, 속도 추정 및 단층 확인을 수행했다. 미세 조정 과정에서는 BERT 모델의 예측 헤드를 새롭게 교체한 후, 모델 전체를 학습 가능한 상태로 두어 사전학습과 동일한 학습률인 0.005를 설정하였다. 미세조정 단계의 입력은 사전학습과 동일하게 송신원 자료가 사용되며, 수신기 배열 자료의 경우 125 × 167, 시간 배열 자료의 경우 167 × 125이다. 출력은 작업에 따라 다르게 설정되는데, 잡음 제거 작업에서는 입력과 동일한 크기로 출력되며, 속도 추정 작업에서는 깊이에 따른 1차원 배열로 크기는 250, 단층 확인 작업에서는 출력이 3개의 클래스로 분류된다.
잡음 제거 작업에서는 표준 편차가 1인 가우시안 노이즈와 표준 편차가 2인 가우시안 노이즈를 사용하여 임의의 잡음을 추가한 후, 수신기 배열과 시간 배열에서 학습된 사전학습 모델을 미세조정하여 이를 얼마나 효과적으로 제거할 수 있는지를 평가하였다. Fig. 4는 가우시안 잡음이 더해진 송신원 모음 자료, 잡음이 제거된 결과 자료, 그리고 입력 자료와 복원된 자료 간의 차이를 보여준다. 본 연구에서 잡음 감소율은 입력 데이터와 잡음이 제거된 데이터 각각의 평균 제곱 오차(MSE)를 기반으로 산출되었다. 구체적으로, 원본 입력 데이터와 레이블 간의 MSE, 그리고 잡음이 제거된 데이터와 레이블 간의 MSE를 계산하여 그 차이를 백분율로 표현하였다. 수신기 배열을 사용하여 사전학습된 모델의 경우, 표준 편차가 1인 가우시안 노이즈가 추가된 자료에서의 잡음 감소율은 97.02%로 나타났으며, 표준 편차가 2인 가우시안 노이즈가 추가된 자료에서는 98.62%의 감소율을 기록하였다. 시간 배열을 사용하여 사전학습된 모델은 표준 편차가 1인 가우시안 노이즈에서 96.62%의 잡음 감소율을 보였고, 표준 편차가 2인 가우시안 노이즈에서는 98.70%의 감소율을 달성하였다. 두 배열을 사용한 모델 간의 잡음 감소율 차이는 미미하였으며, 전반적으로 모두 임의 잡음을 효과적으로 제거하였다. 그러나, 본 실험에서는 임의의 가우시안 잡음에 대해서만 테스트를 수행하였기 때문에, 다른 유형의 잡음에 대해 일반화하기 어렵다. 예를 들어, 특정 수신기에서 발생하는 잡음의 경우 수신기 배열이 더 효과적일 수 있으며, 일정 시간 간격으로 발생하는 잡음의 경우 시간 배열이 더 유리할 수 있다. 따라서, 다양한 유형의 잡음에 대한 성능 평가를 위해서는 추가적인 실험이 필요할 것으로 판단된다.
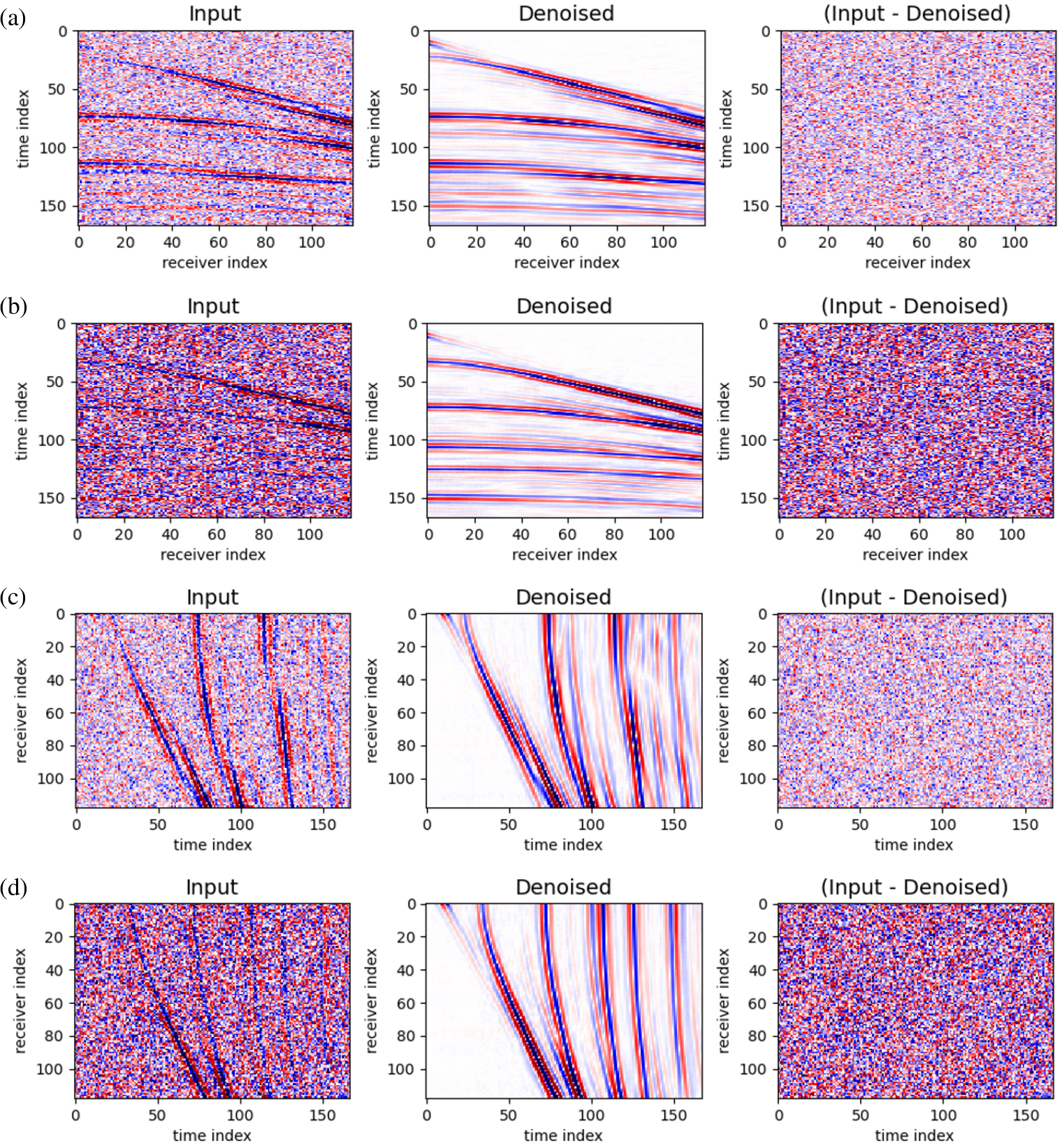
Fig. 4.
Results of denoising shot gathers with added Gaussian noise using (a) and (b) receiver array and (c) and (d) time array. Subfigures (a) and (c) show results with Gaussian noise of standard deviation 1, and subfigures (b) and (d) show results with Gaussian noise of standard deviation 2. Each subfigure displays the noisy shotgather, the denoised result, and the difference between the input and the restored data.
속도 추정 작업에서는 송신원 위치에서의 수직 분포를 예측하였다. 해당 작업 또한 사전학습된 모델을 전이학습을 통해 미세조정하였다. Fig. 5는 시험 자료에 대해 수신기 배열 및 시간 배열에서 미세조정을 통해 예측한 속도 결과를 나타낸다. 두 배열의 미세조정 결과는 전반적으로 속도 값을 잘 예측하고 있으나, 상대적으로 심도가 깊은 위치에서는 시간 배열의 결과가 수신기 배열의 결과보다 우수함을 보여준다. 이는 동일 시간에 다수의 수신기에서 기록된 시간 배열을 사용한 사전학습 모델이, 공간적 분포를 효과적으로 포착하고 해석할 수 있기 때문으로 판단된다. 시험 자료의 MSE 또한 수신기 배열에서 7798, 시간 배열에서 6255로, 시간 배열의 MSE가 수신기 배열보다 더 작았다.
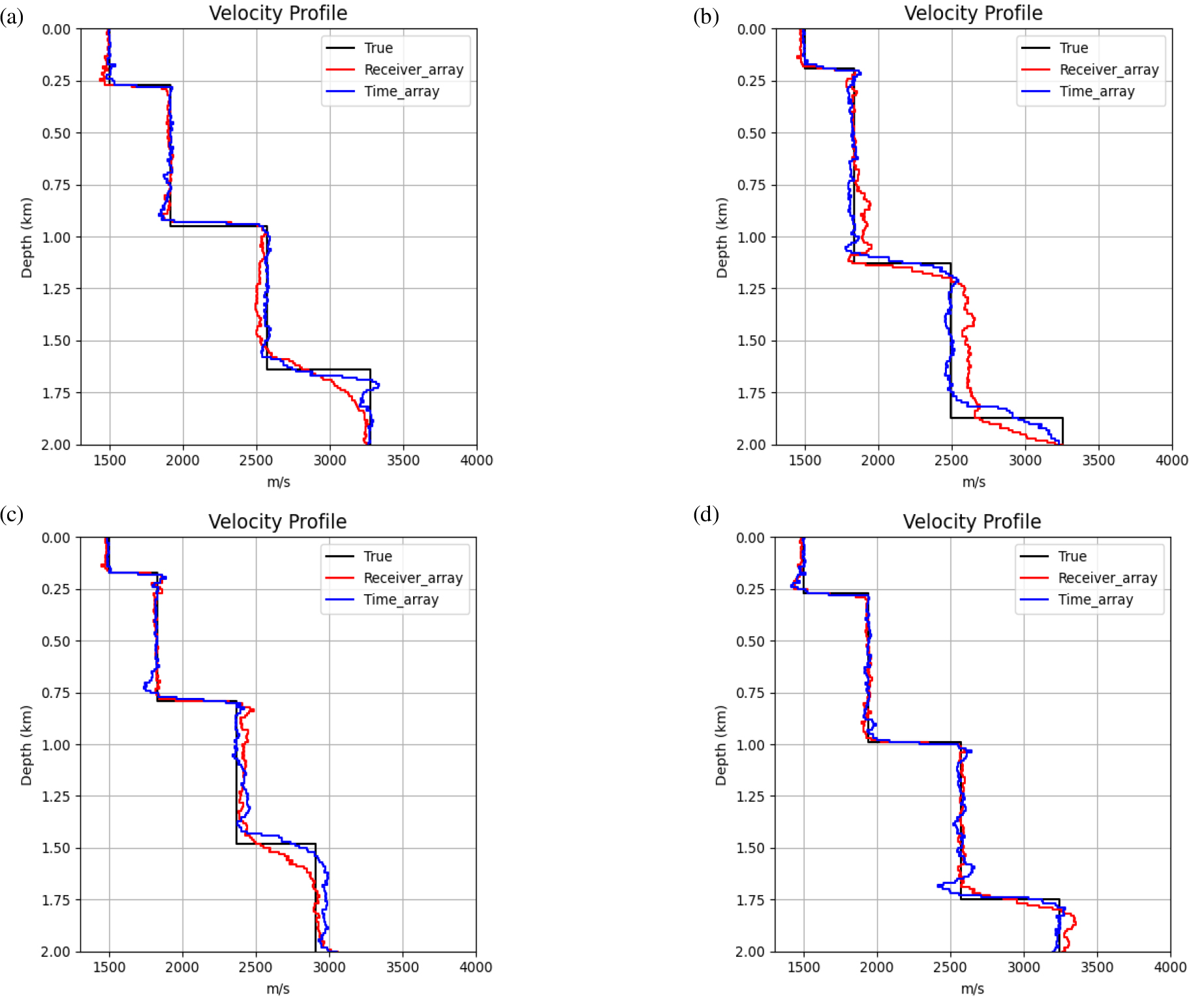
Fig. 5.
Predicted velocity profiles for test data. The black solid line represents the true velocity, the red solid line represents the predicted velocity using the receiver array, and the blue solid line represents the predicted velocity using the time array. Subfigures (a) to (d) show the results for different test datasets.
실험에 사용된 속도 모델 중 절반은 단층이 없는 구조, 나머지 절반은 각각 25%씩 단순한 형태의 정단층과 역단층을 포함한다. 이전 자료처리 과정과 유사하게, 수신기 배열과 시간 배열을 사용하여 사전학습된 모델을 전이학습을 통해 미세조정하여 단층을 확인하는 작업을 수행하였다. Fig. 6은 단층 존재 유무를 확인하는 혼동 행렬(confusion matrix)을 시각적으로 나타낸다. 혼동 행렬은 모델의 분류 결과를 평가하기 위해 예측된 클래스와 실제 클래스를 비교하여, 각 클래스 간의 분류 정확도와 오류를 시각적으로 보여주는 도구이다. 이 실험에서는 세 가지 클래스를 사용하였다: 클래스 0은 역단층, 클래스 1는 정단층, 클래스 2은 단층이 없는 구조를 나타낸다. 이를 통해 모델이 각 클래스에 대해 얼마나 정확하게 분류했는지를 평가할 수 있다. 단층의 형태가 단순하였기 때문에 상대적으로 쉬운 분류 작업이었음에도 불구하고, 수신기 배열을 사용한 모델의 성능은 기대에 미치지 못했다. 수신기 배열을 사용한 모델의 경우, 정확도(Accuracy) 0.82, 정밀도(Precision) 0.81, 재현율(Recall) 0.82, F1 점수(F1 Score) 0.82를 기록하였다. 반면, 시간 배열을 사용한 모델은 모든 평가지표(정확도, 정밀도, 재현율, F1 점수)에서 1.00을 기록하였다. 이는 시간 배열이 동일 시간에 다수의 수신기에서 기록된 자료를 포함하고 있어, 동적 이벤트를 더 잘 포착하고 공간적 분포를 더 정확히 반영할 수 있기 때문으로 판단된다.
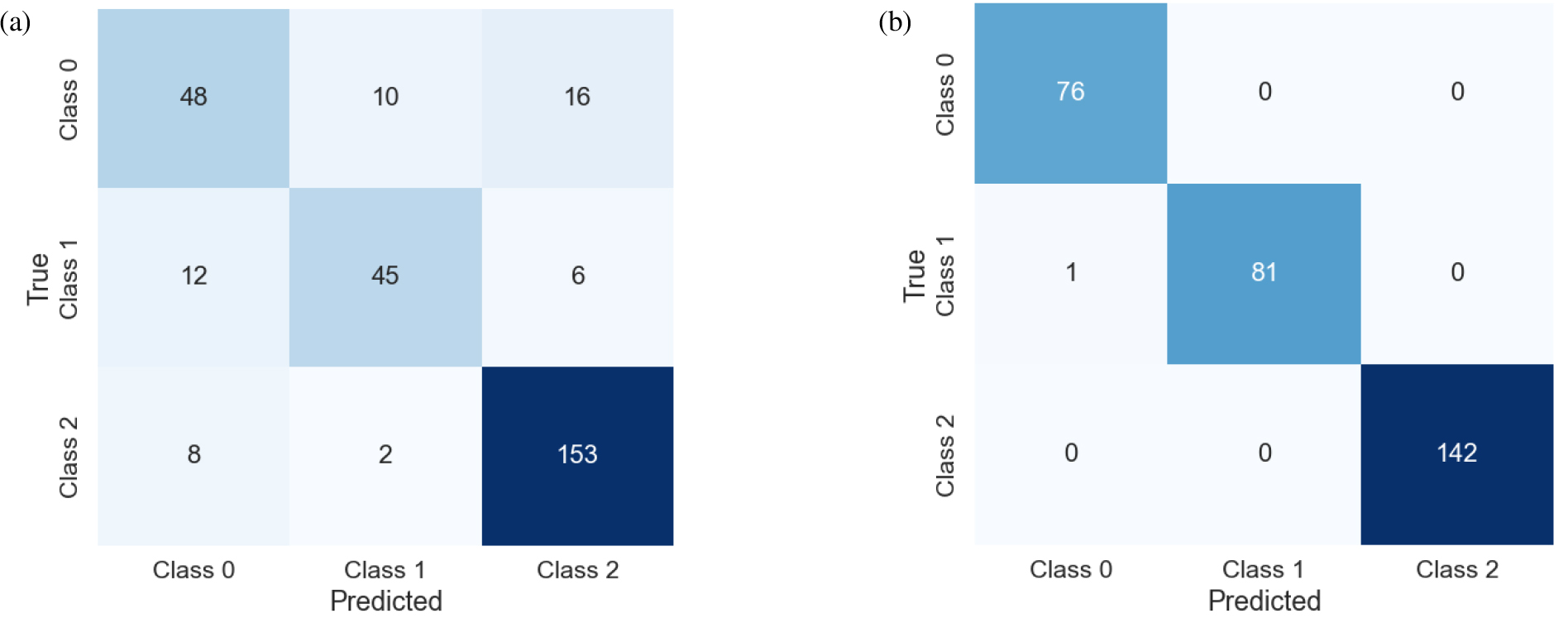
토 의
본 연구는 합성 자료만을 이용하여 실험을 수행하였다. 합성 자료 실험에서도 다양한 속도 모델을 고려하여 학습을 수행하는 것이 이상적이나, 각 속도 모델당 단일 송신원 모음만을 사용하는 제약으로 인해 단순 수평층 모델에 국한되었다. 이는 연구의 일반화 가능성을 제한하는 요인으로 작용한다. 더욱이, 합성 자료는 잡음, 파형, 지오메트리 등 여러 조건에서 실제 탄성파 탐사 자료와 상이하기 때문에, 현장 자료에 적용했을 때 동일한 성능을 보장할 수 없다. 연구에서 활용된 자료처리 작업을 현장 자료에 효과적으로 적용하기 위해서는 여러 요소가 고려되야 한다. 합성 자료를 이용하여 수행한 사전학습과 미세조정 작업들은 정답이 있는 자료를 필요로 하는 지도 학습에 해당하나, 현장 자료에는 정답이 없기 때문에 동일한 방법을 적용할 수 없다. 이전 연구에서는 합성 자료와 현장 자료를 혼합하여 사전학습을 수행한 뒤, 미세조정 단계에서 합성 자료만을 이용한 지도 학습을 수행하고, 이를 현장 자료에 적용하는 방법을 사용하였다(Harsuko and Alkhalifah, 2022). 또한, 미세조정 과정에서는 현장 자료와 합성 자료 간의 괴리를 줄이기 위해 현장 자료의 잡음을 추출해 합성 자료에 추가하기도 하였다. 향후 연구에서 도메인 적응과 반지도 학습 기법을 도입하여 현장 자료에 보다 적합한 모델를 개발하고자 한다.
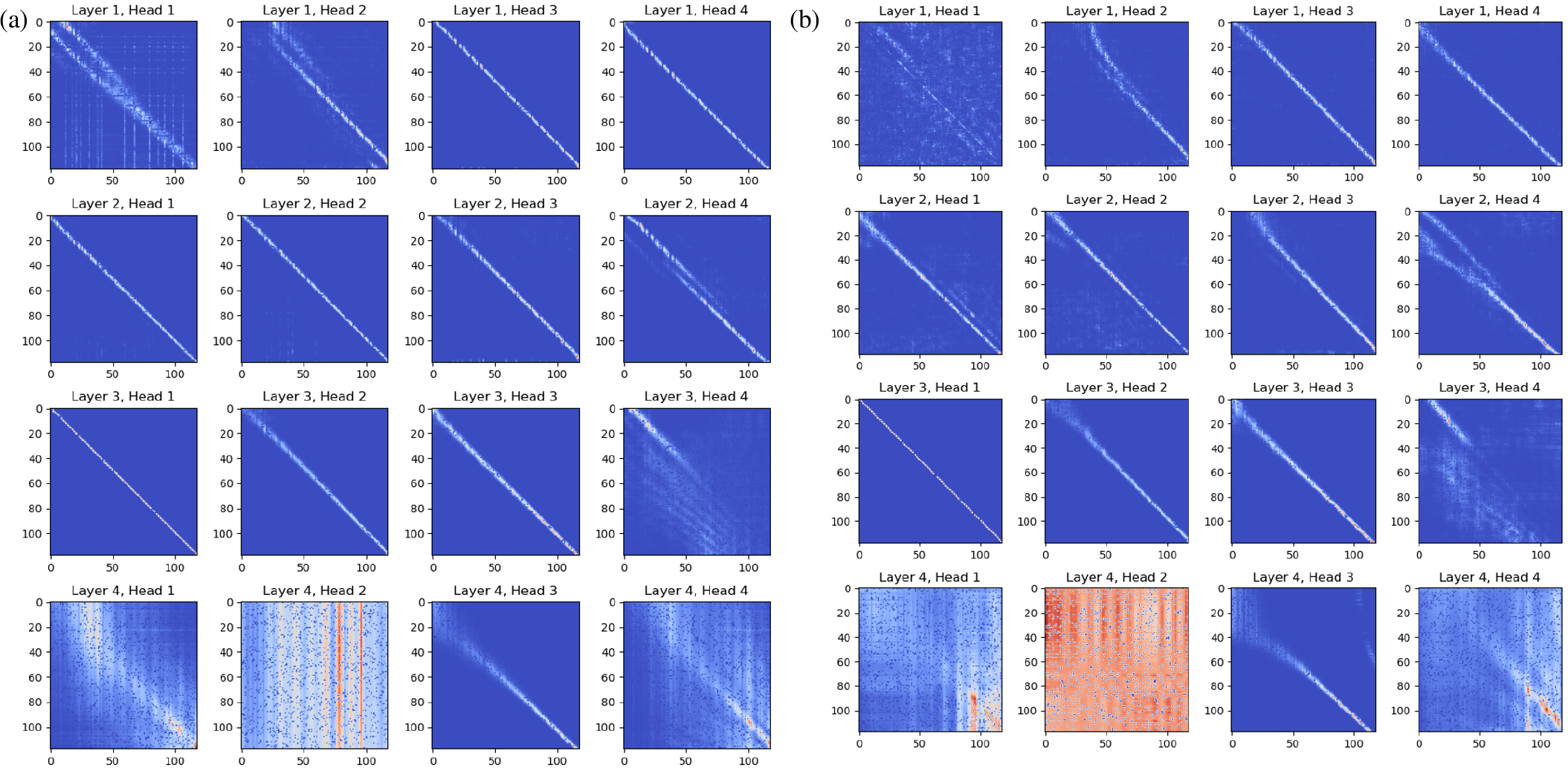
사전학습된 모델을 이용한 자료처리 과정은 사전학습 단계에 비해 계산 시간이 적게 소요된다. 합성 자료를 이용한 수신기 배열에 따른 사전학습에는 약 9,814초가 소요된 반면, 미세조정 과정에서는 잡음 제거에 116초, 속도 추정에 120초, 단층 확인에 115초가 소요되었다. 이는 사전학습을 통해 송신원 모음 자료의 특성을 저장함으로써 탄성파 자료처리 과정을 각각 수행하지 않고 효율적으로 수행할 수 있음을 의미한다. 또한, 사전학습 모델의 유무에 따른 성능 차이를 비교한 결과, 잡음 제거 작업에서 사전학습을 거치지 않은 모델은 1.7% 낮은 잡음 감소율을 기록하였으며, 속도 추정 작업에서는 2.2배 높은 MSE를 나타내어 성능이 저하되었음을 확인하였다. 특히, 단층 확인 작업에서는 사전학습 없이 BERT 기본 모델을 사용한 경우 학습이 원활하게 진행되지 않아 분류 작업을 성공적으로 수행하지 못했다. Fig. 7은 잡음 제거 작업과 속도 추정 작업에서 사전학습의 유무에 따른 수렴 곡선을 나타내고 있으며, 사전학습을 거친 경우 초기 수렴 속도가 빠름을 확인할 수 있다. Fig. 8은 사전학습과 잡음 제거 단계에서의 어텐션 맵을 나타내며, 4개의 어텐션 레이어와 4개의 어텐션 헤드로 구성된 총 16개의 어텐션 맵을 포함하고 있다. 어텐션 맵은 모델이 입력 자료의 어느 부분에 집중하고 있는지를 시각적으로 보여주는 도구로, 모델의 학습 과정과 처리 방식을 이해하는 데 도움을 준다. Fig. 7에서 확인할 수 있듯이, 초기 레이어에서의 어텐션 맵은 유사한 패턴을 보이며, 후반 레이어, 특히 네 번째 층에서 다른 층에 비교하여 상이한 패턴을 나타낸다. 이러한 초기 레이어의 유사성은 전이 학습을 통해 모델이 효율적으로 일반적인 특징을 학습했음을 보여주며, 자료처리 작업에서 공통적으로 중요한 정보를 포착하고 있음을 시사한다.
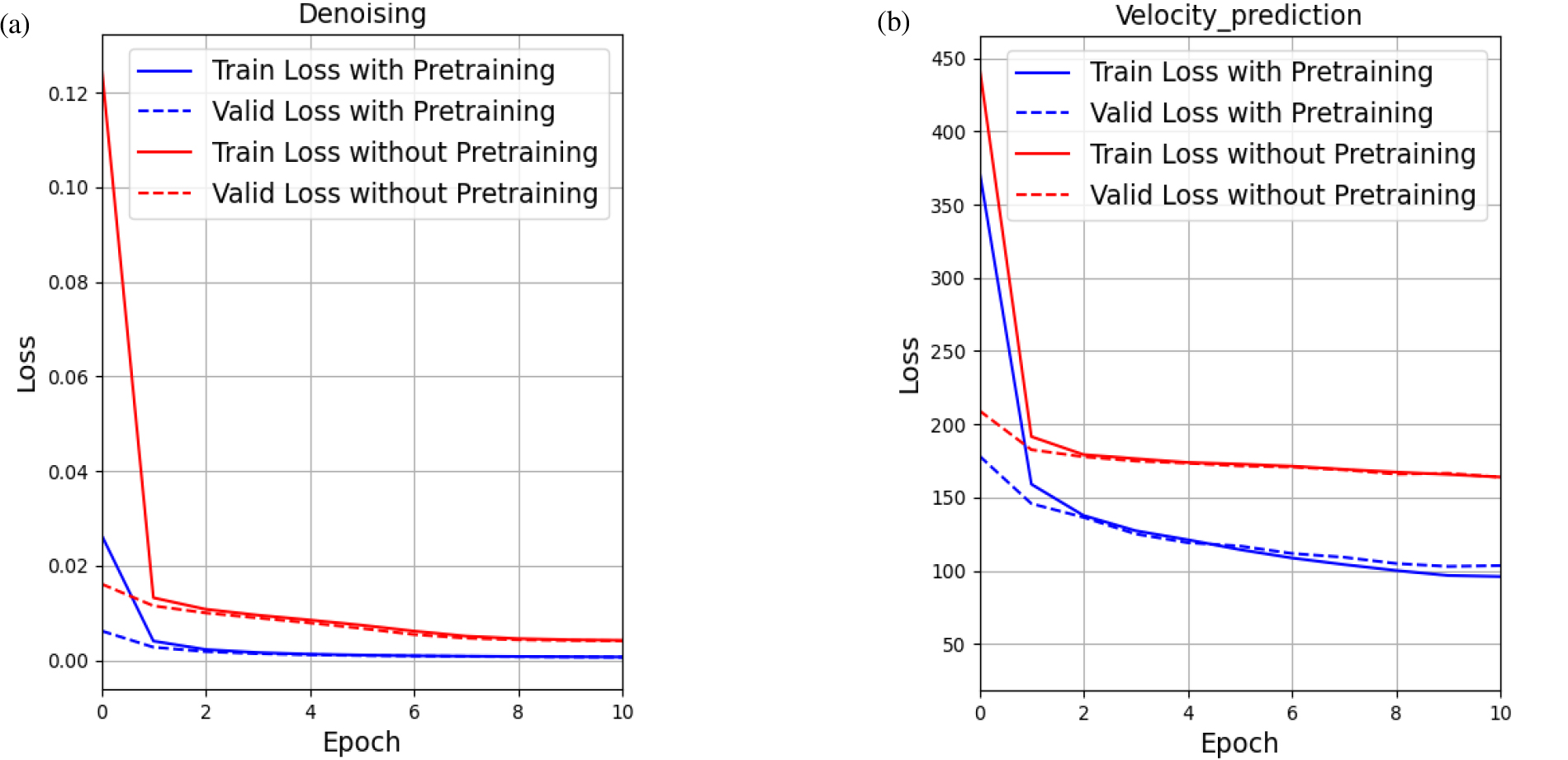
Fig. 7.
Loss curves for (a) denoising tasks and (b) velocity prediction tasks across 10 epochs. The solid blue lines represent the training loss with pretraining, the dashed blue lines represent the validation loss with pretraining, the solid red lines represent the training loss without pretraining, and the dashed red lines represent the validation loss without pretraining.
학습에 사용된 BERT 모델의 하이퍼파라미터는 고정된 값으로 설정되었으며, 구체적인 값은 L = 4 (어텐션 레이어), H = 256 (히든 레이어 차원), A = 4 (어텐션 헤드)였다. 본 연구의 목적이 단순한 형태의 합성 자료를 통해 모델의 기본적인 성능을 평가하는 데 있었기 때문에, 하이퍼파라미터를 고정하여 실험을 진행했지만 복잡한 구조의 합성 자료 또는 현장 자료 적용시에는 하이퍼파라미터 튜닝을 통해 모델의 성능을 극대화하는 과정이 필요할 것이다. 또한, 본 연구에서는 다른 머신러닝 기법들과의 성능 비교가 충분히 이루어지지 않았다. 향후 연구를 통해 BERT 모델과 다른 기법들 간의 성능을 비교하여 각각의 장단점을 명확히 하고 최적의 접근 방식을 제시할 필요가 있다.
결 론
본 연구에서는 BERT 기반 사전학습을 활용하여 탄성파 자료처리의 효율성을 증대시키고, 송신원 모음 배열에 따른 탄성파 처리 작업에서의 성능을 비교 평가하고자 하였다. 실험은 단층을 포함한 단순 속도 모델에서 생성된 단일 합성 송신원 모음 자료를 이용하여 진행하였다. 사전학습 단계에서는 수신기 배열과 시간 배열에 따라 마스킹된 입력 자료를 복원 하는 방식으로 학습이 진행되었고, 이후 사전학습된 모델을 전이학습을 통해 미세조정하여 잡음 제거, 속도 추정, 단층 확인 등의 작업을 수행하였다. 두 배열 모두 임의 잡음 제거에서는 우수한 성능을 보였으며, 성능 차이는 미미하였다. 표준 편차가 2인 가우시안 노이즈가 섞인 자료에서도 수신기 배열과 시간 배열이 각각 98.62%와 98.70%의 잡음 감소율을 기록하였다. 속도 추정 작업에서는 시간 배열이 수신기 배열보다 깊은 심도에서 더 높은 정확도를 보였고 오차도 더 작았다. 단층 확인 작업에서도 수신기 배열을 사용한 모델의 정확도는 0.82였지만, 시간 배열을 사용한 모델의 정확도는 1.00에 가까웠다. 이는 시간 배열이 동적 이벤트를 더 잘 포착하고, 공간적 분포를 더 정확히 반영할 수 있기 때문으로 판단된다.
본 연구는 BERT 기반 사전학습이 탄성파 자료처리에 효과적으로 적용될 가능성을 제시하였다. 특히, 시간 배열을 활용한 사전학습 모델이 공간적 분포를 포착하고 해석하는 데 있어서 상대적으로 우수한 성능을 보였다는 점에서 의의가 있다. 그러나, 단순 속도 모델로부터 얻은 단일 합성 송신원 모음을 이용한 실험이기 때문에 현장 자료에 직접적으로 해당 네트워크 구조를 적용하기에는 한계가 존재한다. 따라서, 도메인 적응 및 비지도 학습과 같은 다른 머신러닝 기법의 도입이 필요하며 현장 자료에 적합한 BERT 모델을 구현하는 연구가 추가로 필요할 것으로 판단된다.
