

서 론
이 론
라플라스 영역 지도학습 기반 탄성파 역산
손실 함수
라플라스 영역 파형 역산 네트워크
송신원 추정을 위한 목적 함수
훈련 데이터 세트
해저 지층 모델
라플라스 영역 파동장
심층 신경망 훈련
신경망 입력
지도학습
송신원 추정
관측 자료 생성
라플라스 영역 전파형 역산
수치 예제
Marmousi 속도 모델
Pluto 속도 모델
토 의
딥러닝 기반 탄성파 역산
라플라스 영역 지도학습 기반 탄성파 역산
송신원 추정의 중요성
현장 자료 적용 가능성
향후 연구 방향
결 론
서 론
속도 모델과 같은 지하 물성 모델을 정확하게 추정하는 것은 탄성파 탐사 자료 처리에서 매우 중요하면서도 도전적인 작업이다. 탄성파 탐사로 얻은 관측 자료를 해석하여 지하 지질 구조 및 매질의 물성을 추정하기 위한 대표적인 기법으로는 구조보정 속도 분석(Liu and Bleistein, 1995), 중간점 속도 분석(Yilmaz, 2001), 주시 토모그래피(Zhang et al., 1998), 그리고 전파형 역산(Tarantola, 1984) 등이 있다. 이 중 가장 정확하고 고해상도의 속도 모델을 추정할 수 있는 전파형 역산은 시간 영역에서 최초로 제안되었으며(Tarantola, 1984; Gauthier et al., 1986), 이후 주파수 영역 역산(Pratt and Worthington, 1990)과 라플라스 영역 역산(Shin and Cha, 2008)으로 확장되었다. 이러한 전파형 역산 기술들은 지속적인 이론적 발전을 통해 상업적으로 성공하였으며, 현재 현장 자료 처리에 널리 사용되고 있다. 그러나, 전파형 역산은 기울기 기반 최적화 방법의 내재적 한계로 인해 국부 최소값(local minima) 문제가 발생할 수 있으며, 주기 놓침 현상(cycle-skipping), 저주파수 성분 부족, 초기 속도 모델에 대한 의존성과 같은 요인들이 역산 결과가 참 속도 모델에 수렴하는 것을 방해한다(Virieux and Operto, 2009).
컴퓨터 하드웨어 성능의 급격한 발전으로 방대한 양의 데이터 활용이 가능해짐에 따라, 딥러닝은 다양한 분야에서 주목받는 기술로 부상하였으며, 지구물리학 분야에서도 그 적용 사례가 꾸준히 증가하고 있다. 특히, 기존 전파형 역산의 한계를 해결하기 위해 제안된 딥러닝 기반 탄성파 역산 기술들은 우수한 역산 성능을 입증하였다(Adler et al., 2021). 이러한 딥러닝 기반 탄성파 역산 기술들은 전통적인 전파형 역산의 고질적인 문제인 주기 놓침 현상, 초기 속도 모델에 대한 의존성 등을 극복할 수 있는 강력한 대체제임을 보여주었다(Adler et al., 2021).
예를 들어, Yang and Ma (2019)는 딥러닝 기반 탄성파 역산이 전파형 역산에 비해 저주파수 성분 부족에 덜 민감하며, 주기 놓침 문제에도 취약하지 않음을 보여주었다. 또한, 전파형 역산은 초기 속도 모델에 민감한 반면, 지도학습을 이용한 딥러닝 역산은 정확한 초기 속도 모델의 필요성을 제거할 수 있으며(Araya-Polo et al., 2019; Wang and Ma, 2020; Zhang and Lin, 2020; Li et al., 2020), P파 속도 대신 신경망 가중치를 역산 매개변수로 활용하는 네트워크 매개변수화 접근법은 신경망의 정규화 효과를 통해 초기 속도 모델에 대한 민감도를 효과적으로 완화하였다(Wu and McMechan, 2019; He and Wang, 2021; Zhu et al., 2022; Dhara and Sen, 2022). 추가적으로, Wu et al. (2020)은 딥러닝 기반 탄성파 역산이 탄성파 자료 내 잡음 및 위상 차이에 대해 견고하다는 것을 입증하였다. 딥러닝 기반 탄성파 역산 관련 연구는 지금도 활발하게 진행되고 있으며, 국내에서도 딥러닝 기술을 이용하여 주시 토모그래피 또는 전파형 역산을 구현한 사례들이 존재한다(Jo and Ha, 2022; Jo and Ha, 2023a; Jo and Ha, 2023b; Jo and Ha, 2024).
그러나 훈련 자료에 크게 의존하는 지도학습 기반 탄성파 역산 연구들은 주로 인공 합성자료를 대상으로 하고 있으며(Araya-Polo et al., 2019; Yang and Ma, 2019; Wang and Ma, 2020; Zhang and Lin, 2020; Li et al., 2020; Liu et al., 2023), 현장 자료 적용에 필요한 송신원 추정 문제를 다루는 딥러닝 기반 탄성파 역산 연구는 아직 찾을 수 없었다. 다양한 송신원을 사용해 훈련 자료를 생성하는 방식으로 송신 파형 문제를 일부 완화할 수 있으나, 이를 위해서는 훈련 자료가 더 많이 필요하므로 훈련 비용이 증가하며, 인공 송신 파형을 사용함에 따라 현장 송신 파형에 대한 일반화 성능 저하 문제가 발생할 수 있다(Farris et al., 2023). 현장 탐사 자료 취득 단계에서는 정확한 송신원 파형을 알아내기 어려우므로, 자료 처리 단계에서 성공적인 역산을 위해서는 정확한 송신원 매개변수를 추정하는 것이 중요하다. 역산에 사용되는 송신원의 파형이 실제 송신원과 크게 다를 경우 역산 결과가 참 속도 모델에 수렴하지 못하거나 계산 비용이 증가할 수 있다. 따라서, 안정적이고 정확한 역산 결과를 얻기 위해서는 지하 물성 매개변수 뿐만 아니라 송신원 매개변수를 정확하게 추정하는 것이 중요하다.
본 연구에서는 라플라스 영역 지도학습 기반 탄성파 역산에 송신원 추정 과정을 추가하였다. 송신원 추정 알고리즘은 기존 라플라스 영역 전파형 역산에서 사용하는 것과 동일한 알고리즘을 채택하였으며(Shin et al., 2007), 뉴턴법을 이용하여 송신원 매개변수를 반복적으로 갱신하였다. 이 때, 각 라플라스 감쇠 상수에 따른 송신 파형은 진폭 정보만을 가진다. 추정된 송신원 진폭을 이용해 관측 자료를 디컨벌루션한 뒤, 이를 임펄스 반응 자료로만 훈련시킨 네트워크의 입력으로 사용하였다. 수치 실험을 통해 단일 송신 파형으로 학습시킨 네트워크가 새로운 송신 파형으로부터 생성된 관측 자료에 대해 민감하게 반응함을 확인하였다. 이때, 추정한 송신원 매개변수로 디컨벌루션한 관측 자료를 입력으로 사용하면 네트워크가 정확한 속도 모델을 예측할 수 있음을 확인하였다. 추가적으로, 본 연구에서는 라플라스 영역 딥러닝 기반 탄성파 역산을 위한 새로운 심층 신경망을 제안하며, 지도학습 훈련 시 기존 연구와 정량적으로 비교 분석하였다. 마지막으로 토의 절에서는 제안된 접근법의 시사점, 현장 자료 적용 가능성 및 라플라스 영역 딥러닝 기반 탄성파 역산의 향후 연구 방향에 대해 논의하였다.
이 론
라플라스 영역 지도학습 기반 탄성파 역산
탄성파 탐사에서 지하 물성 모델을 얻기 위해 인공 탄성파 송신원을 이용해 인공 지진파를 생성한 다음 수신기 모음을 통해 탄성파 기록을 취득한다. 이렇게 취득한 탄성파 기록은 시간 영역 파동장으로 표현할 수 있으며, 본 연구에서는 일정한 밀도를 가진 2차원 음향파 파동 방정식을 사용하였다.
위 식에서 는 P파 속도, 는 공간, 는 시간, 은 2차 미분 연산자, 는 시간 영역 파동장, 그리고 는 시간 영역 송신원을 의미한다. 라플라스 영역 파동 방정식은 위의 시간 영역 파동 방정식에서 라플라스 변환을 통해 얻을 수 있다(Shin and Cha, 2008).
위 식에서 는 라플라스 감쇠 상수, 는 라플라스 영역 파동장, 그리고 는 라플라스 영역 송신원을 의미한다. 라플라스 영역 파동장과 송신원은 각각 시간 영역 파동장과 송신원을 라플라스 변환을 수행한 것으로, 아래와 같이 나타낼 수 있다.
다음으로, 지도학습 기반 탄성파 역산 알고리즘은 다음과 같이 표현할 수 있다.
위 식에서 는 예측된 속도 모델, 은 비선형 연산자의 역할을 수행하는 심층 신경망, 는 입력 탄성파 기록, 는 모델 매개변수인 신경망의 가중치를 의미한다. 심층 신경망은 탄성파 기록을 입력 받아 주어진 가중치를 통해 속도 모델을 출력한다. 본 연구에서는 탄성파 기록으로 라플라스 영역 파동장을 사용하였다.
시간 영역 파동장 대신 초동 주시나 라플라스 영역 파동장을 입력으로 활용하면 역산 결과의 해상도가 상대적으로 낮아지지만, 입력 및 출력 데이터 크기가 상당히 감소하여 제한된 계산 자원 내에서도 대규모 훈련 데이터 세트를 이용할 수 있으며, 심층 신경망 훈련 또한 가속화할 수 있다. 선행 연구에서는 심층 신경망이 파동의 초동 주시(first-arrival traveltimes)만으로도 속도 모델의 주요 특징을 학습할 수 있음을 입증한 바 있다(Jo and Ha, 2023b). 파동의 주시 정보만 사용하는 주시 토모그래피와 달리 라플라스 영역 파동장을 사용하면 여러 감쇠 상수를 이용하여 천부 및 심부 지층의 정보도 포함시킬 수 있다(Jo and Ha, 2023a). 반면에, 송신 파형과 무관한 주시와 달리, 라플라스 영역 파동장을 사용할 경우 송신원의 영향을 고려해야 한다.
손실 함수
지도학습을 기반으로 한 심층 신경망 훈련 알고리즘은 참 속도 모델과 예측된 속도 모델 간의 불일치를 기반으로 손실 함수(loss function)를 정의하여 네트워크 가중치를 최적화하는 것을 목표로 한다. 이 과정은 손실 함수를 최소화하는 방향으로 모델 매개변수를 반복적으로 갱신하는 것을 포함한다. 본 연구에서는 손실 함수를 정의하기 위해 평균 절대 오차(mean absolute error, MAE), 평균 제곱 오차(mean square error, MSE), 그리고 구조 유사성 지수(Structural Similarity Index, SSIM)를 도입하였다. MAE는 다음과 같이 나타낼 수 있다.
위 식에서 는 번째 참 속도 모델이며, 는 번째 예측된 속도 모델이다. MSE는 다음과 같다.
이미지의 세부적인 지역 구조를 포착할 수 있는 SSIM은 다음과 같다(Wang et al., 2004).
위 식에서 와 는 각각 두 이미지 내의 윈도우(window)를 의미하고 와 는 및 윈도우의 국소 평균, 와 는 표준편차, 는 와 의 교차 공분산을 의미한다. SSIM은 추출한 두 이미지 윈도우 사이의 유사성을 측정하며 SSIM 값이 1에 가까울수록 유사성이 높음을 의미한다. 손실 함수 값이 감소하도록 모델 매개변수를 갱신하기 위해 SSIM의 평균 손실은 다음과 같이 정의하였다.
본 연구에서는 MAE, MSE 및 SSIM의 조합을 통해 최종 손실 함수를 다음과 같이 정의하였다(Jo and Ha, 2022; Jo and Ha, 2023a; Jo and Ha, 2023b).
라플라스 영역 파형 역산 네트워크
이전 연구(Jo and Ha, 2023a)에서는 시간 영역 파동장 대신 라플라스 영역 파동장을 네트워크 입력으로 받기 위해 Tomography_CNN (Jo and Ha, 2022)을 간단히 수정하여 사용하였다. 본 연구에서는 속도 모델의 예측 정확도를 향상시키기 위해 라플라스 영역 파동장의 특징을 보다 효과적으로 포착할 수 있도록 신경망 구조를 새롭게 설계하고 기존 Tomography_CNN과 구분하기 위해 라플라스 영역 파형 역산 네트워크(Laplace-domain Waveform Inversion Network, LWI_Net)이라 명명하였다. 자체 설계한 네트워크에 대한 상세한 내용은 아래와 같다.
LWI_Net은 인코더-디코더 구조를 기반으로 하며, 총 아홉 개의 합성곱 블록, 네 개의 전치 합성곱(transposed convolution) 층, 하나의 1 × 1 깊이별 분리 합성곱(Kaiser et al., 2017) 층, 그리고 시그모이드(sigmoid) 함수를 포함한다(Fig. 1 참조). 각 합성곱 블록은 배치 정규화(batch normalization)(Loffe and Szegedy, 2015), Gaussian Error Linear Unit (GELU) 활성화 함수(Hendrycks and Gimpel, 2016), 그리고 깊이별 분리 합성곱 층으로 구성된다. GELU는 컴퓨터 비전, 자연어 처리, 자동 음성 인식 등 다양한 분야에서 ReLU 및 ELU보다 일관되게 우수한 성능을 보인 것으로 알려져 있다(Hendrycks and Gimpel, 2016).
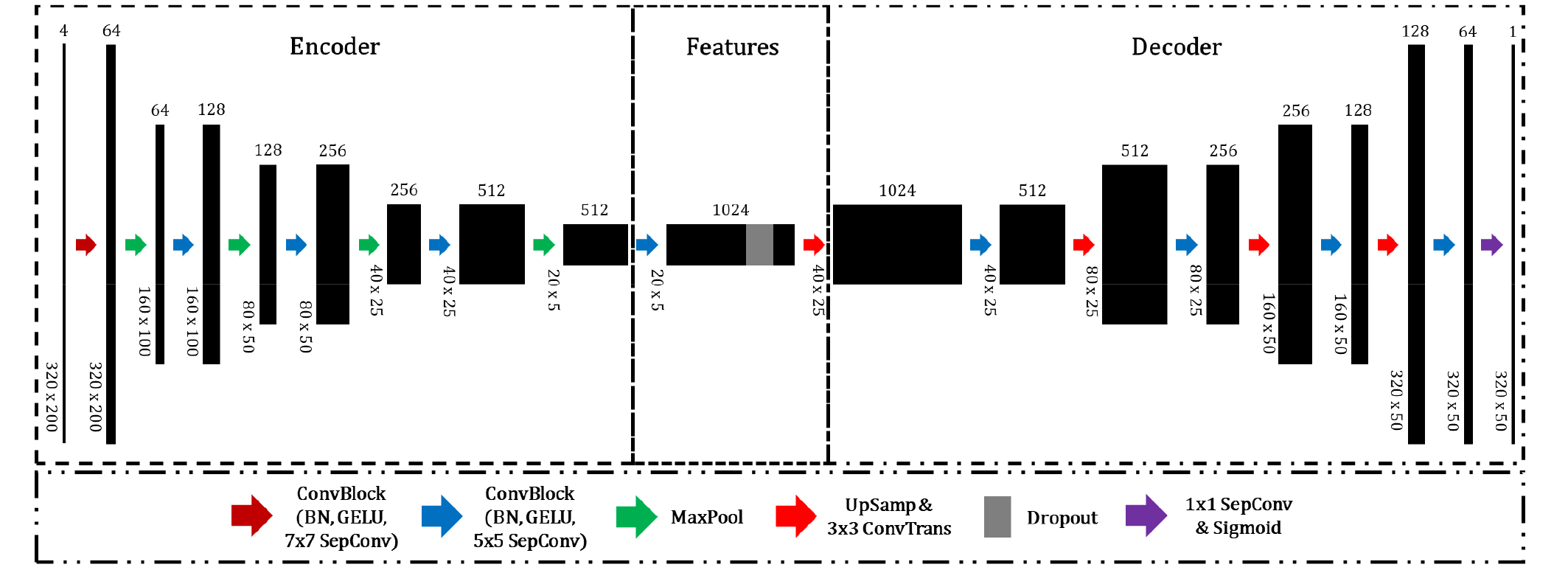
Fig. 1
Architecture of LWI_Net. Each ConvBlock performs two convolutional operations: batch normalization, GELU activation, and depthwise separable convolutions. The first ConvBlock captures long-range dependencies in seismic data through a large receptive field. Features extracted by the encoder are partially discarded using a dropout layer. The final layer outputs the velocity model and applies a sigmoid function to constrain the velocity values within a specific range.
깊이별 분리 합성곱은 계산 효율성을 향상시키면서도, 탄성파 역산 문제에서 일반 합성곱과 유사한 성능을 유지할 수 있는 것으로 보고된 바 있다(Jo and Ha, 2022; Jo and Ha, 2023b). 또한, LWI_Net의 입력 채널 수는 라플라스 감쇠 상수의 개수에 해당하므로, 각 채널에 대해 독립적으로 공간 방향의 합성곱을 수행하는 깊이별 분리 합성곱의 적용은 이론 상으로도 타당하다. 초기 합성곱 블록은 7 × 7 크기의 깊이별 분리 합성곱을 적용하며, 이는 탄성파 이미지 내 장거리 의존성(long-range dependency)을 효과적으로 포착하기 위해 큰 커널 크기를 의도적으로 도입한 것이다. 이후 합성곱 블록들은 5 × 5 크기의 깊이별 분리 합성곱을 적용하며, 각 블록에서는 두 차례의 합성곱 연산이 수행된다.
인코더 단계에서는 채널 차원을 순차적으로 64, 128, 256, 512, 1024로 확장하는 동시에, 최대 풀링(max-pooling)을 통해 입력 데이터의 크기를 점진적으로 축소한다. 인코더의 마지막 층에는 0.5의 드롭아웃 비율이 적용되어, 일부 특성 정보를 무작위로 제거함으로써 과대적합을 방지한다. 이후 디코더 단계에서는 채널 차원을 1024, 512, 256, 128, 64로 점차 감소시키며, 압축된 데이터를 최종 속도 모델 크기로 확장한다. 체커보드 아티팩트(checkerboard artifacts) 현상을 완화하기 위해, 3 × 3 전치 합성곱 층과 업샘플링(upsampling)을 결합한 전략을 채택하였다(Odena et al., 2016). 최종 출력 층은 1 × 1 깊이별 분리 합성곱과 시그모이드 함수를 적용하여 단일 채널의 속도 모델을 생성하며, 이때 출력 속도 값은 1.5 km/s에서 5.0 km/s 범위 내로 제한된다.
일반적인 의미 분할(semantic segmentation)을 위한 이미지 대 이미지 변환(image-to-image translation) 모델과 달리, 탄성파 역산 문제는 입력과 출력 이미지가 서로 다른 도메인에 속한다. 즉, 탄성파 도메인의 데이터를 속도 모델 도메인으로 변환해야 하며, 이로 인해 입력과 출력 간의 이미지 차원 크기의 차이가 크게 나타난다. 이러한 차원 불일치와 약한 공간적 대응(spatial correspondence)으로 인해, U-Net (Ronneberger et al., 2015) 등의 구조에서 흔히 사용되는 스킵 연결(skip connection)은 탄성파 역산 문제에 적용하기 어렵다. 따라서 도메인 변환 및 속도 모델 복원은 오직 네트워크가 추출한 저차원 잠재 벡터(latent vector)에 전적으로 의존해야 한다. 그럼에도 불구하고 인코더-디코더 구조는 도메인 간 변환과 입력ㆍ출력 이미지 크기의 불일치를 효과적으로 처리할 수 있어 이러한 작업에 적합한 구조로 간주된다.
네트워크의 가중치는 훈련 과정 중 발생할 수 있는 불안정을 완화하기 위해 절단 정규분포(truncated normal distribution) 방식으로 초기화된다(Hanin and Rolnick, 2018). LWI_Net은 총 15,832,588개의 모델 매개변수를 포함한다. 심층 신경망은 일반적으로 과대매개변수화(over-parameterization)되어 있으며, 이는 모델의 매개변수 수가 훈련 데이터의 양을 크게 초과함을 의미한다. 그러나 여러 경험적 연구에 따르면, 이러한 과대매개변수화가 오히려 최적화 성능과 일반화 성능을 동시에 향상시킬 수 있음이 보고된 바 있다(Allen-Zhu et al., 2019a; Allen-Zhu et al., 2019b; Cao and Gu, 2020).
송신원 추정을 위한 목적 함수
본 연구에서는 Shin et al. (2007)에서 제안하는 송신원 추정 알고리즘을 채택하였다. 라플라스 영역에서의 송신원 추정을 위한 로그 목적 함수는 다음과 같이 나타낼 수 있다.
위 식에서 는 번째 송신원, 번째 수신기에서의 관측 파동장, 는 임펄스 반응, 는 송신 파형의 진폭을 의미하며, 는 라플라스 감쇠 상수이다. 라플라스 영역에서는 위상 항이 없기 때문에 추정된 송신원 매개변수 는 감쇠 상수별 진폭 값만 포함하게 된다. 이때, 로 표기하면 에 대한 목적함수의 그래디언트(gradient) 및 헤시안(Hessian)은 다음과 같이 나타낼 수 있다(Ha et al., 2012).
위 식에서 는 송신원 개수, 는 수신기 개수를 의미한다. 따라서, 송신원 매개변수는 다음과 같이 완전 뉴턴법(full Newton method)을 이용해 반복적으로 갱신할 수 있다.
훈련 데이터 세트
본 연구에서는 2차원 현장 규모의 대량의 인공 속도 모델을 자동으로 생성하고, 각 속도 모델에 대해 라플라스 영역 파동 전파 모델링을 수행하여 훈련 데이터 세트를 구축하였다. 라플라스 영역 파동장을 입력으로 사용하면 시간 영역 파동장에 비해 입력 데이터의 크기가 크게 줄어들기 때문에 제한된 계산 자원으로도 심층 신경망 훈련이 가능하며, 큰 격자를 가진 속도 모델도 사용할 수 있다. 훈련에 사용한 속도 모델은 균일한 밀도의 등방성 2차원 속도 모델들이며, 라플라스 영역 파동장은 2차원 라플라스 영역 음향파 파동 방정식(식 (2))을 이용해 생성하였다.
해저 지층 모델
해저 지층의 구조적 특성을 반영하기 위해 층서, 단층, 암염 구조 등을 가진 합성 속도 모델을 생성하였다. 총 40,000개의 속도 모델을 생성하였으며, 각 속도 모델은 격자 간격이 100 m로 320 × 50개의 격자점을 가지며, 따라서 속도 모델의 크기는 32 km × 5 km가 된다. 배경 속도는 1.5 km/s을 가진 물층부터 시작하여 최대 3.5 km/s까지 층이 깊어질수록 증가하며, 속도 모델을 생성할 때마다 각 층의 속도마다 무작위로 변동을 주었다. 생성된 속도 모델 내 층의 개수는 최소 10개에서 최대 25개 사이의 균일 분포를 따른다. 층서 구조 모델의 경우 각 층의 인터페이스마다 수평 층(flat layer), 경사 층(dipping layer), 습곡 층(fold layer) 등을 무작위로 생성하였으며, 단층 및 암염 구조 모델의 경우 이러한 층서 구조 모델에 단층 또는 암염을 추가하였다. 단층면은 평면으로 가정하여 최소 3개에서 최대 9개까지의 단층을 다양한 위치와 기울기를 갖도록 서로 겹치지 않게 배치하였다. 암염의 모양은 가우시안 정규분포 또는 타원 함수를 사용하여 정의한 뒤, 최소 1개에서 최대 3개까지의 암염을 임의의 위치에 추가하였으며, 이때 암염에서의 P파 속도는 4.5 km/s에서 5 km/s 범위의 값을 가진다. 출력 속도 모델의 크기는 1 × 320 × 50 (속도 모델 채널 × 너비 방향 격자 개수 × 깊이 방향 격자 개수)이며, 생성된 합성 속도 모델의 예시는 Fig. 2에 나와 있다.
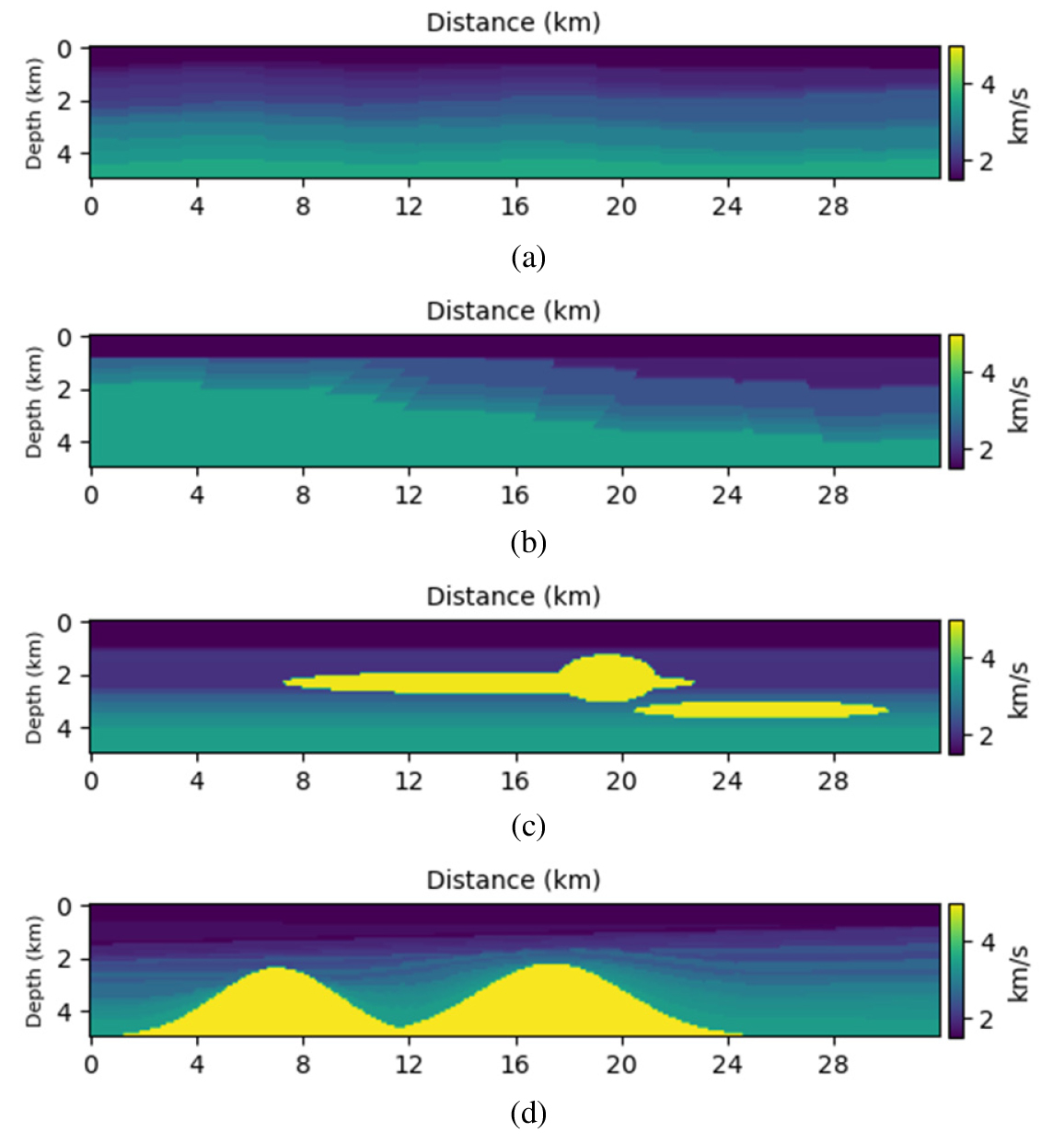
라플라스 영역 파동장
라플라스 감쇠 상수는 4, 6, 8, 그리고 10 s-1으로 총 4개를 사용하였으며, 송신원 파형은 디락 델타 함수로, 이때 진폭 값은 모든 감쇠 상수에 대해 1로 고정하였다. 따라서, 신경망은 다양한 송신 파형에 대한 정보를 학습하지 못한다. 수치 모델링은 공간 2차 유한 차분법을 이용해 수행하였으며 경계 조건은 Perfectly Matched Layer (PML) 경계 조건을 사용하였다(Cohen, 2002). 현장 해양 탄성파 탐사를 시뮬레이션하기 위해 200개의 송신원과 100개의 수신기로 구성된 2차원 견인 스트리머 취득 조건을 채택하였다. 송신원과 수신기 간의 간격은 100 m이며, 최소 오프셋은 200 m, 최대 오프셋은 10.1 km이다. 속도 모델의 격자 간격 또한 100 m이므로 각 송신원마다 320개의 격자점 중 수신기가 위치한 100개의 격자점에만 라플라스 영역 파동장 값이 존재하고, 수신기가 없는 나머지 영역의 값은 0으로 할당하였다. 입력 라플라스 영역 파동장의 크기는 4 × 320 × 200 (라플라스 감쇠 상수 채널 × 너비 방향 격자 개수 × 송신원 개수)이 된다. Fig. 3은 속도 모델로부터 2차원 견인 스트리머 취득 조건으로 얻은 라플라스 영역 파동장의 예시를 보여준다.
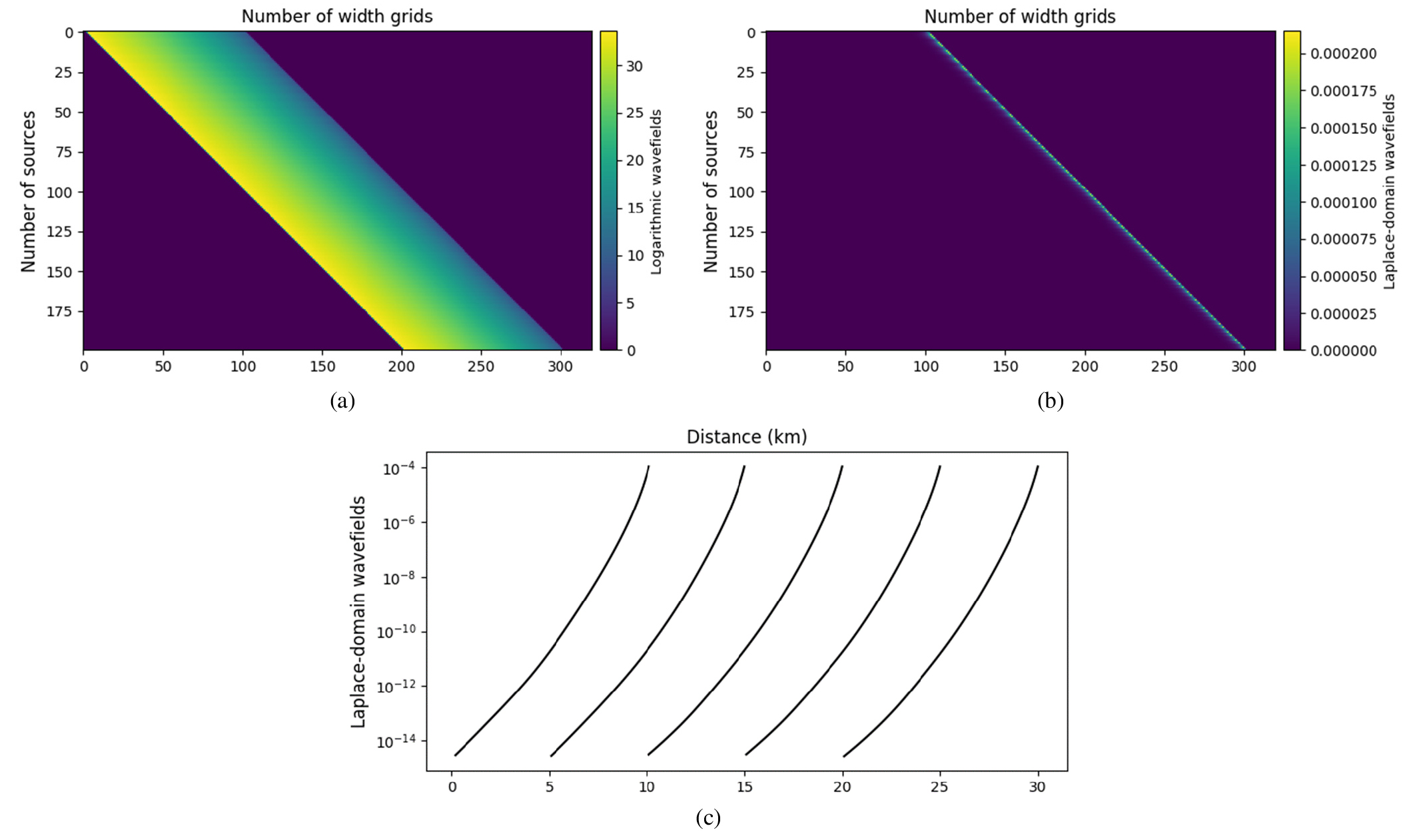
Fig. 3
Laplace-domain wavefield examples using 2D towed-streamer acquisition. The acquisition setup consists of an array of 200 sources and 100 receivers. (a) Input data of size 320 × 200 fed into the network. (b) Original Laplace-domain wavefields and, (c) Laplace-domain wavefields profiles generated by the 1st, 50th, 100th, 150th, and 200th sources with a Laplace damping constant of 4 s-1.
심층 신경망 훈련
신경망 입력
라플라스 영역 파동장을 활용한 신경망 훈련을 용이하게 하기 위해 아래와 같이 절대값에 자연로그를 취했다. 그런 다음, 결과 음수 값에 -1을 곱하여 입력 데이터 값을 전부 양수로 변환하여 사용하였다(Fig. 3(a)).
라플라스 영역 파동장(Fig. 3(b)~3(c))을 그대로 입력으로 사용한 경우 훈련 성능이 저조하게 나타났다. 이는 파동장이 송신원 근처에서만 큰 값을 가지고 나머지 값들은 송신원으로부터의 거리에 따라 지수적으로 감쇠되기 때문에 신경망 가중치 갱신 시 송신원 근처의 값만 주로 사용되는 문제가 나타난 것으로 판단된다. 또한, 음의 로그 파동장으로 인한 훈련 성능 저하는 활성화 함수의 결과로 간주되는데, 활성화 함수는 큰 음수 값에 대해 0을 출력하여 심층 신경망 훈련 중에 기울기 소실 문제를 유발할 수 있다. 그리고 감쇠 상수가 큰 경우 원본 파동장을 다루기 위해서는 배정도 부동소수점 정밀도(double-precision floating-point)가 요구되므로 로그 파동장을 사용하는 것이 메모리 측면에서 더 효율적이다. 양의 로그 파동장을 네트워크 입력으로 사용할 때 음의 로그 파동장보다 훈련도 안정적이고 우수한 성능을 보인다는 점을 고려하여, 송신원 추정을 포함한 모든 수치 예제에 대해 식 (14)를 입력으로 사용하였다.
지도학습
지도학습을 위해 전체 데이터 세트는 훈련, 검증 및 테스트 세트에 각각 80%, 10%, 10% 만큼 할당하였다. 따라서 신경망 학습에 사용된 훈련 세트는 32,000쌍이며, 검증 및 테스트 세트는 각각 4,000쌍으로 구성된다. Adam 옵티마이저의 변형인 AMSGrad 옵티마이저(Sashank et al., 2019)를 채택하였으며, 이때 초기 학습률은 , 여기서 은 사용된 GPU의 개수를 의미한다. 배치 사이즈는 로 설정하였으며 총 200번의 에포크(epochs)로 신경망을 훈련시켰다. 학습률을 매 에포크마다 5%씩 감소시키는 학습률 스케줄러를 사용하였으며, 모든 에포크 중 가장 낮은 검증 손실을 가진 신경망 가중치를 저장하였다. 위 하이퍼파라미터들은 실험을 통해 경험적으로 구한 값으로, 실험 조건이 달라질 경우 조정이 필요할 수 있다. 실험은 Nvidia Geforce RTX 3090 GPU 카드 4장을 이용하여 수행하였으며, LWI_Net의 훈련 시간은 에포크 당 약 1분 50초가 소요되었다. 이는 동일한 훈련 데이터 크기 및 컴퓨팅 환경에서 수행된 선행 연구(Jo and Ha, 2023a)의 에포크 당 약 1분 56초보다 약 5% 향상된 결과다.
테스트 세트에 대해 훈련된 신경망으로 속도 모델을 예측한 결과, 테스트 손실은 0.2519가 나왔으며, 테스트 MAE은 0.0580, MSE는 0.0180, SSIM은 0.8241가 나왔다. 예측한 속도 모델은 Fig. 4에 제시되어 있으며, 전반적으로 참 속도 모델과 유사한 구조를 보이나, 해상도는 낮아진 예측 결과를 볼 수 있다. 참 속도 모델은 고해상도 모델인 반면에 예측 결과는 저해상도 모델이므로 손실 값이 다소 크게 나오는 것을 확인할 수 있다. 주목할 점은 본 연구에서 선행 연구(Jo and Ha, 2023a)보다 더 복잡한 속도 모델을 사용했음에도 불구하고, 더 우수한 예측 성능을 달성하였다. 다만, 본 연구와 선행 연구 간의 비교는 동일한 속도 모델을 기반으로 한 것이 아니므로, 절대적인 수치 비교보다는 상대적 경향을 확인하기 위한 참고용으로 제시한다. 두 모델의 정량적 비교 결과는 Table 1에 정리하였으며, 이러한 훈련 속도 및 예측 정확도의 향상은 신경망 구조의 설계가 딥러닝 기반 탄성파 역산의 성능에 있어 핵심적인 요소임을 시사한다. 예측 결과를 통해 훈련된 신경망이 해저 지층 모델의 주요 특징을 효과적으로 학습하였으며, 층의 개수 및 경계면, 암염의 위치와 형태 등을 부드럽게 구축하는 것을 확인할 수 있다.
송신원 추정
본 절에서는 Marmousi 속도 모델(Versteeg, 1994) 및 Pluto 속도 모델(Stoughton et al., 2001)의 두 가지 벤치마크 모델을 이용한 수치 예제를 통해 훈련 자료와 다른 송신 파형이 지도학습 기반 탄성파 역산에 미치는 영향에 대해 분석한다. 정확한 송신원 매개변수를 추정하기 위해 초기 모델에 견고한 라플라스 영역 전파형 역산에 송신원 추정 과정을 통합하였다. 그런 다음, 송신원 추정을 통해 얻은 송신원 매개변수로 관측 자료를 디컨벌루션한 다음, 네트워크의 입력으로 사용하였다. 라플라스 영역에서의 디컨벌루션은 각 감쇠 상수별 파동장에 대해 단순한 진폭 스케일링으로 구현된다.
관측 자료 생성
라플라스 영역 수치 모델링을 통해 관측 자료를 얻기 전에, 신경망 훈련에 사용된 속도 모델과 동일한 크기로 맞추는 작업부터 수행하였다. 먼저, 원본 Marmousi 속도 모델 중 일부 구간을 선택하여 이를 32 km × 5 km, 격자 간격 100 m의 속도 모델로 수정하였다. 그 후, 깊이가 1 km인 물층을 추가하였으며, 해당 속도 모델은 Fig. 5(a)에 제시되어 있다. 다음으로, Pluto 속도 모델은 격자 간격이 50 fts (15.24 m)로 너비가 104,000 fts, 깊이가 30,050 fts의 크기를 갖는다. 따라서, Pluto 속도 모델도 마찬가지로 훈련에 사용된 속도 모델의 크기에 일치하도록 보간하였다(Fig. 5(b)). 그런 다음, 신경망 학습에 사용한 송수신기 배열과 동일한 2차원 견인 스트리머 취득 조건을 가지고 각 속도 모델로부터 라플라스 영역 파동장을 생성하였다. 이때 두 가지 벤치마크 모델 모두 4, 6, 8, 10 s-1의 감쇠 상수에 대해 각각 5, 4, 3, 2 크기의 진폭 값을 주어 관측 자료를 생성하였다.
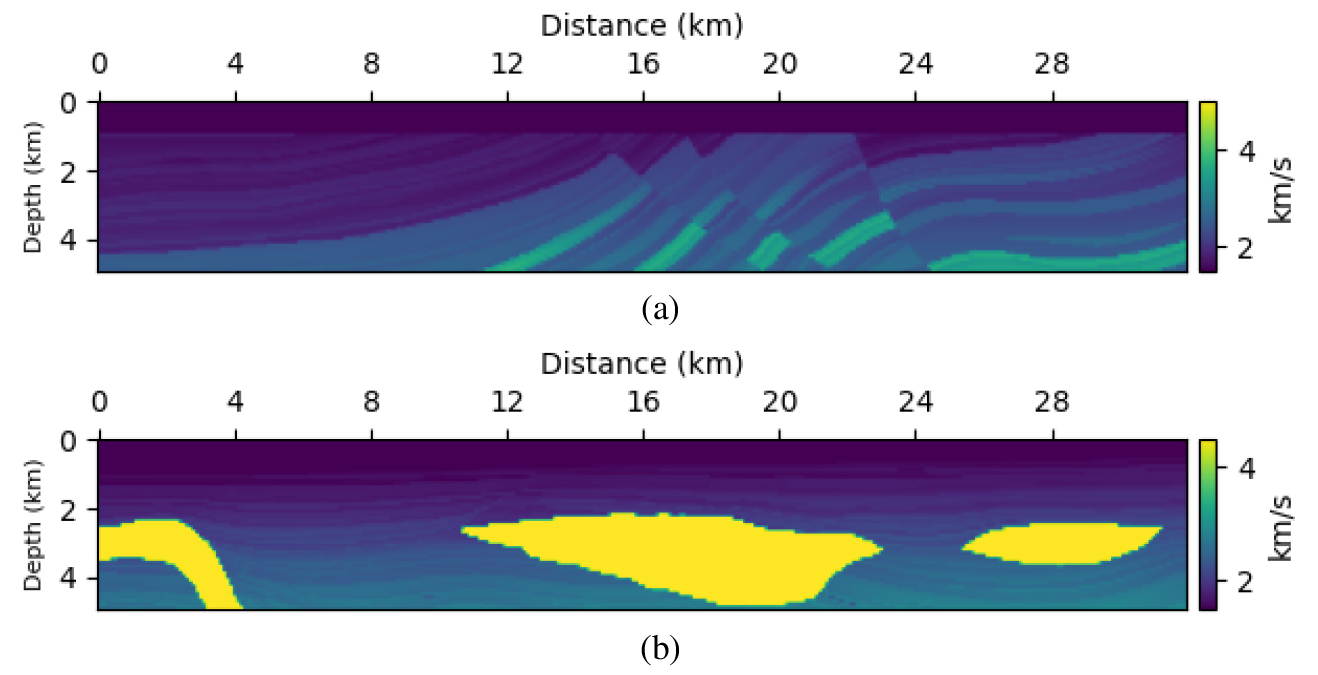
Fig. 5
(a) The modified Marmousi velocity model (Versteeg, 1994). (b) The modified Pluto velocity model (Stoughton et al., 2001).
라플라스 영역 전파형 역산
본 절에서는 송신원 추정 과정이 포함된 라플라스 영역 전파형 역산 조건에 대해 설명한다. 물층의 정보를 명시적으로 제공하지 않는 딥러닝 방법(네트워크 입력으로 오직 관측 자료만 주입)과 달리 전파형 역산에는 물층의 정보를 이용하였으며, 송신원 추정과 마찬가지로 L2-norm 기반 목적 함수를 채택하였다. 전파형 역산에 사용하는 관측 자료도 로그 파동장(식 (14))이기 때문에 송신원 추정과 동일하게 L2-norm 기반 목적 함수는 로그 목적 함수와 동일한 역할을 수행한다. 초기 속도 모델은 1.5 km/s의 배경 속도를 가진 물층에서 시작하여, 깊이에 따라 최대 3.5 km/s까지 선형적으로 증가하는 선형 모델을 사용하였다. 전파형 역산은 Nesterov Accelerated Gradient (NAG) 옵티마이저(Nesterov, 1983)를 사용하여 고정된 스텝 길이(step length)를 가지고 총 100번의 반복을 수행하였다. 해당 실험은 Nvidia GeForce RTX 3090 GPU 단일 장비에서 수행되었으며, 두 벤치마크 모델에 대한 수치 예제 모두 계산 시간은 약 1분 26초가 소요되었다.
수치 예제
Marmousi 속도 모델
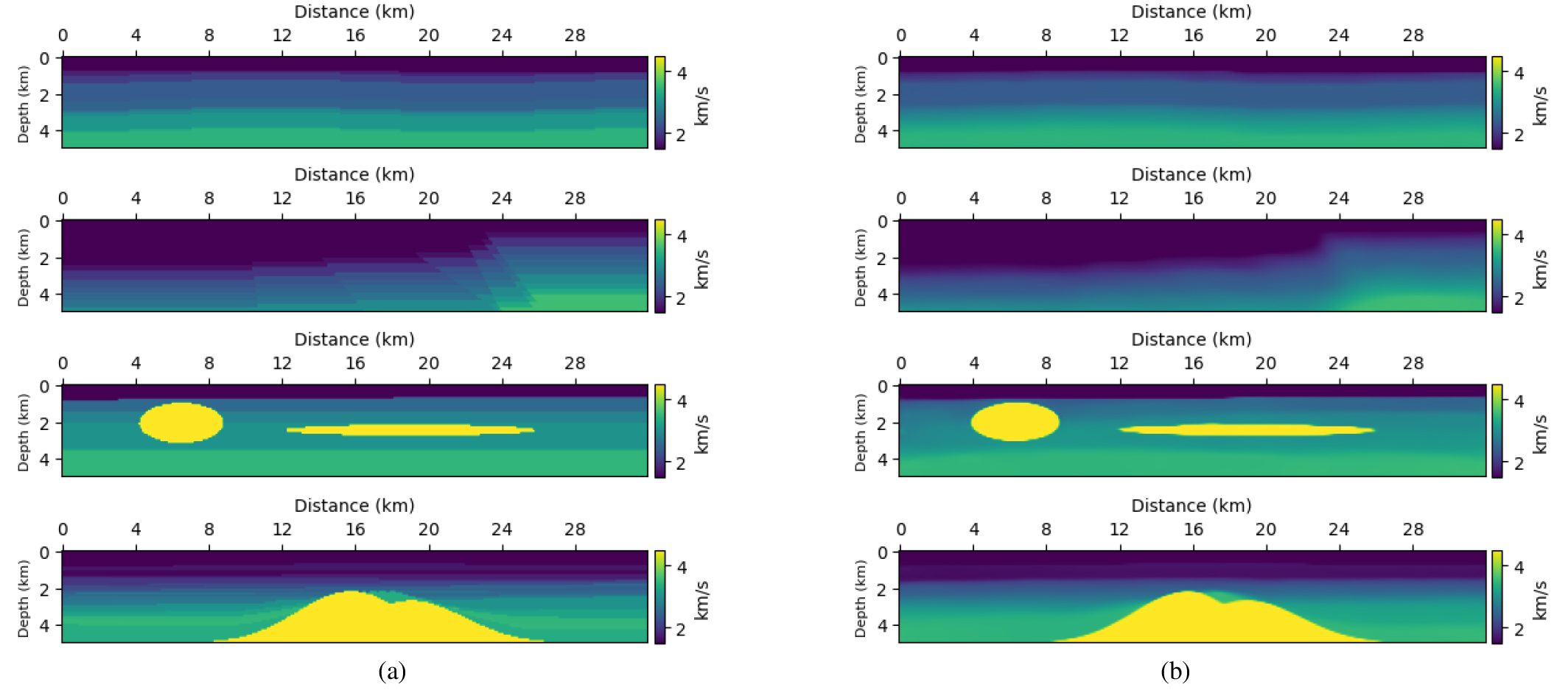
먼저, 송신원 추정 및 디컨벌루션을 적용하지 않은 관측 자료를 네트워크에 입력한 결과는 Fig. 6(a)에 제시되어 있다. 그림을 보면 네트워크가 참 속도 모델과 전혀 상이한 예측 결과를 산출하는 것을 확인할 수 있다. 이는 네트워크가 송신원의 진폭 값이 오직 1인 경우만 학습했기 때문이며, 입력된 파동장이 다른 진폭 값을 갖고 있더라도 이를 진폭 1에서 생성된 파동장으로 잘못 인식하고 속도 모델을 예측하기 때문이다. 이로 인해 네트워크는 관측 자료의 값의 변화가 속도 모델에 기인한 것인지, 송신 파형에 기인한 것인지 구분할 수 없는 한계를 보인다. 다음으로, 송신원 추정을 수행한 결과, 감쇠 상수 4, 6, 8, 10 s-1에 대해 각각 4.702, 3.775, 2.828, 1.884 크기의 진폭 값을 추정하였으며, 이는 실제 값에 거의 근접한 수준이다. 이렇게 추정된 진폭 값을 가지고 관측 자료를 디컨벌루션한 후, 네트워크에 입력한 결과는 Fig. 6(b)에 제시하였다. 그림에서 확인할 수 있듯이, 네트워크의 출력은 참 속도 모델과 높은 유사성을 보이며 지질학적으로 타당한 예측 결과를 도출하였다. 송신원 추정 유무에 따른 속도 모델 예측 결과의 정량적 비교는 Table 2에 정리하였다.
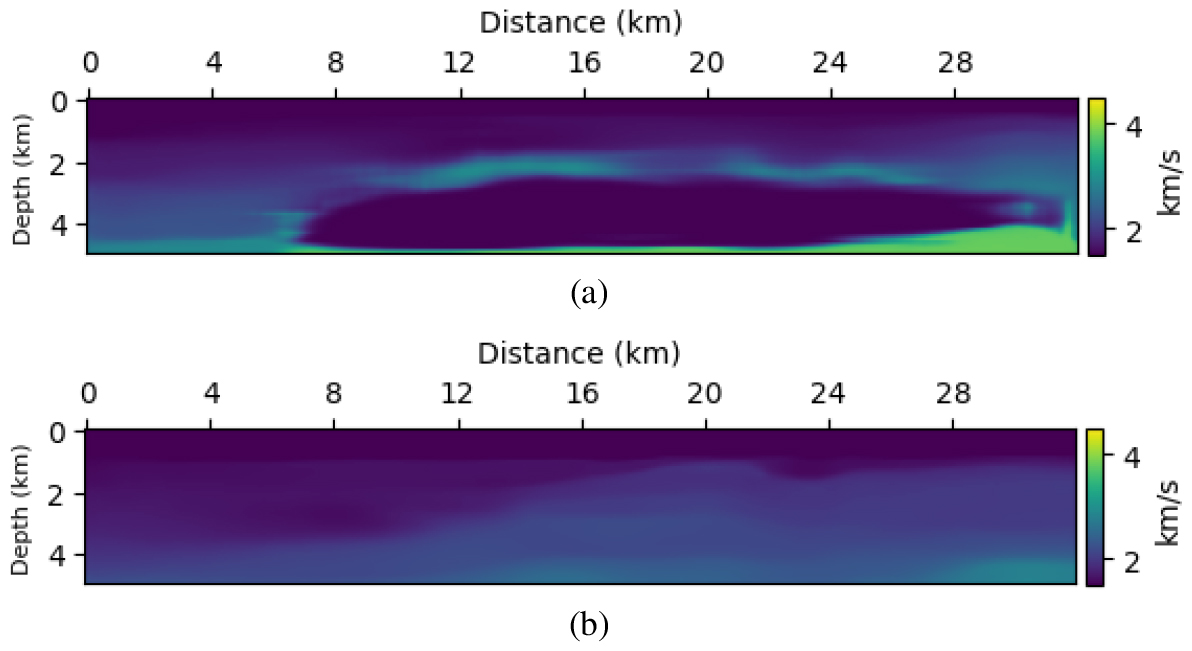
Table 2.
Comparison of model losses obtained with and without source estimation for the modified Marmousi velocity model.
| Before | After | |
| Total loss | 1.4529 | 0.8305 |
| MAE | 0.4121 | 0.2079 |
| MSE | 0.3726 | 0.1057 |
| SSIM | 0.3319 | 0.4832 |
Pluto 속도 모델
동일한 절차를 Pluto 속도 모델에 적용하였다. 먼저, 송신원 추정 및 디컨벌루션을 적용하지 않은 관측 자료를 입력한 경우의 결과는 Fig. 7(a)에 제시되어 있으며, 네트워크는 참 속도 모델과 명확히 다른 결과를 산출하였다. 이후, 송신원 추정을 수행한 결과, 감쇠 상수 4, 6, 8, 10 s-1에 대해 각각 4.736, 3.819, 2.898, 1.966의 진폭 값을 추정하였고, 이는 참 값에 거의 일치하였다. 추정된 진폭 값을 가지고 디컨벌루션한 관측 자료를 네트워크에 입력한 결과는 Fig. 7(b)에 나타나 있다. Marmousi 모델과 마찬가지로 지질학적으로 의미 있는 구조와 참 속도 모델에 가까운 양상을 보였다. 송신원 추정 유무에 따른 속도 모델 손실 값들은 Table 3에 정리하였다. 두 가지 수치 예제를 통해 동일 송신 파형으로 학습된 네트워크가 다른 송신 파형에 민감하다는 사실을 알 수 있었다. 그러나, 정확한 송신원 매개변수를 사전에 추정할 수 있다면, 추가적인 지도학습 없이도 다양한 송신 파형에 대해 안정적이고 정확한 예측이 가능함을 실험적으로 검증하였다.
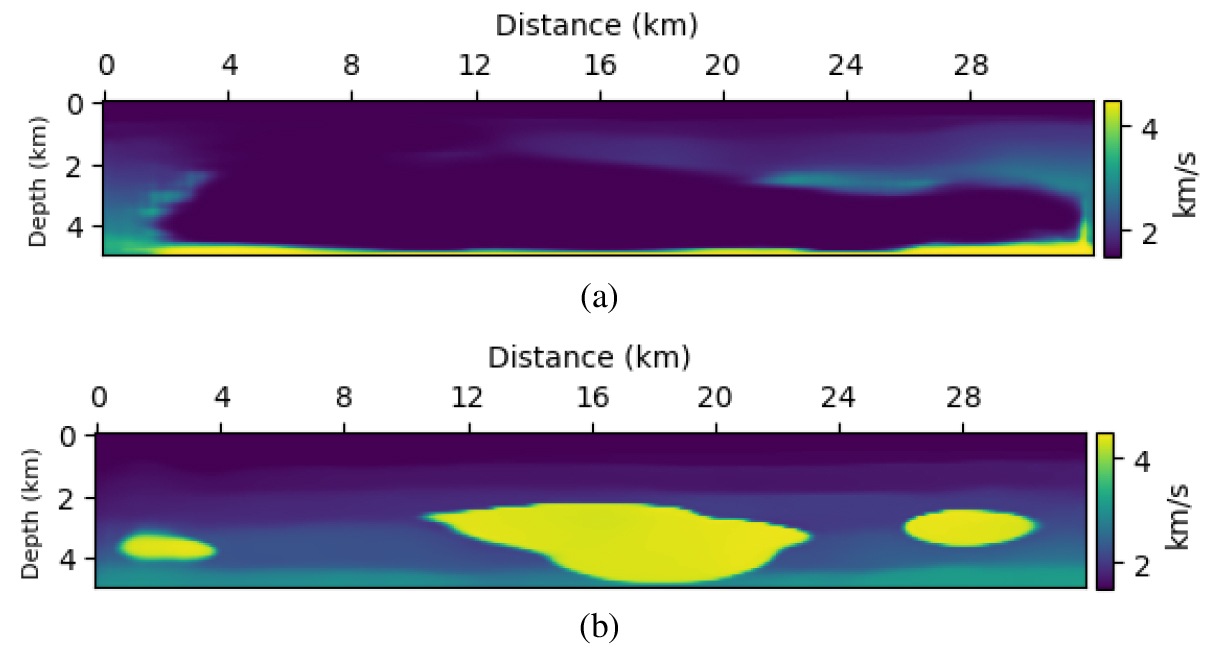
토 의
본 절에서는 딥러닝 기반 탄성파 역산 기술의 특징에 대해 논의하고, 라플라스 영역 지도학습 기반 탄성파 역산에 대한 심층 분석을 제시한다. 딥러닝 기반 탄성파 역산은 전파형 역산을 포함한 전통적인 역산 기법에 비해 여러 이점을 제공한다.
딥러닝 기반 탄성파 역산
딥러닝은 이론적으로 보편적 근사 정리(universal approximation theorem) 이론에 근간을 두고 있으며(Hornik et al., 1989), 이 이론이 실제로 효과적으로 적용되기 시작한 것은 얕은 신경망에서 층을 깊게 쌓는 심층 신경망 구조가 도입된 이후이다(Goodfellow et al., 2016). 딥러닝 기반 탄성파 역산은 기존 전파형 역산의 한계점인 주기 놓침 현상, 초기 속도 모델에 대한 의존성 등을 해결하기 위해 제안되었으며, 다양한 딥러닝 기술을 활용하여 전파형 역산을 성공적으로 대체하거나 보완하였다. 이러한 딥러닝 기반 탄성파 역산은 순수 데이터 기반 접근법, 물리 기반 신경망 활용법, 인코더-디코더 구조 신경망 활용법, 신경망 매개변수화 기법, 물리 정보 기반 신경망 활용법 등으로 구분할 수 있다(Pyun and Park, 2022).
더 포괄적인 관점에서 딥러닝 기반 탄성파 역산은 지배 방정식의 사용 유무에 따라 크게 순수 데이터 기반 접근법과 물리 기반 신경망을 이용한 접근법으로 구분할 수 있다. 순수 데이터 기반 접근법의 경우 입력 데이터와 출력 데이터 간의 함수를 직접 학습하는 방식을 채택하며, 물리 기반 신경망을 이용한 접근법의 경우 지배 방정식을 신경망 훈련 과정에 포함시키거나 역산 결과를 제약하는 정규화 역할로서 활용한다. 최근 연구 동향은 순수 데이터 기반 접근법의 단점을 보완해 나가는 방향으로 진행되고 있으며, 앞으로 딥러닝 기반 탄성파 역산은 탄성파 자료 처리 분야에서 가치가 더욱 높아질 것으로 기대된다(Pyun and Park, 2022).
라플라스 영역 지도학습 기반 탄성파 역산
지도 학습 기반 탄성파 역산은 순수 데이터 기반 접근법에 해당하며, 주시 토모그래피나 전파형 역산과 같은 기존 역산 기법들과 달리 지구물리학적 지배 방정식이나 사전 지식을 반영한 초기 모델이 필요하지 않다. 대량의 훈련 데이터로부터 심층 신경망을 훈련시켜 모델 매개변수를 자동으로 최적화하며, 이로 인해 부정확한 초기 속도 모델로 인한 국소 최소값 문제를 피할 수 있다. 신경망 훈련에는 상당한 계산 비용이 수반되지만, 일단 훈련이 완료되면 예측 단계에서의 계산 비용은 매우 미미하다.
본 연구에서는 시간 영역 파동장 대신 라플라스 영역 파동장을 입력 데이터로 활용하여 현장 규모의 속도 모델을 예측하였다. 라플라스 영역 파동장은 시간 영역 파동장에 비해 데이터 크기가 상당히 작기 때문에 신경망 훈련도 가속할 수 있으며, 이는 심층 학습의 주요 한계 중 하나인 높은 훈련 비용을 효과적으로 완화할 수 있다는 점에서 의의가 있다. 단, 라플라스 영역 파동장을 입력 데이터로 사용하면 시간 영역 파동장에 비해 데이터 자체의 정보가 감소하므로 역산 결과의 해상도가 저하된다. 그럼에도 불구하고 해저 지층을 모사한 합성 속도 모델 예제에서 우수한 성능을 달성하였으며, 적절한 신경망 구조를 설계함으로써 예측 정확도뿐만 아니라 훈련 효율성 또한 개선할 수 있음을 선행 연구와의 비교를 통해 확인하였다. 본 연구에서 예측한 속도 모델은 최종 속도 모델로 사용하기 보다는, 전파형 역산과 같은 후속 자료 처리를 위한 초기 모델로 활용하여 역산의 초기 모델 민감도 문제를 완화하는 데 기여할 수 있다.
송신원 추정의 중요성
전파형 역산의 경우 관측 자료와 모델링한 자료의 오차를 목적 함수로 정의하고, 이를 최소화하는 방향으로 속도 매개변수를 반복적으로 갱신한다. 이와 유사하게, 송신원 추정 문제 또한 비슷한 형태의 목적 함수를 정의하여 송신원 매개변수를 성공적으로 추정할 수 있다(Park and Pyun, 2015). 그러나, 딥러닝 기반 탄성파 역산에서는 송신원 추정 문제를 다룬 사례가 거의 없으며, 대부분의 연구는 고정된 송신 파형을 사용하여 심층 신경망을 훈련시키거나 모델링한 자료를 생성한다. 본 연구에서 두 가지 벤치마크 모델에 대한 수치 예제를 통해, 고정된 파형에서만 학습된 신경망이 다양한 송신 파형에 대해 일반화되지 못하고 잘못된 역산 결과로 이어질 수 있음을 확인하였다. 이러한 결과는 딥러닝 기반 탄성파 역산에서 송신원 추정의 중요성을 시사하며, 이를 통합적으로 고려하는 접근이 필요함을 보여준다. 라플라스 영역에서는 진폭 매개변수만을 고려하기 때문에 송신원 추정이 비교적 단순하지만, 시간 영역이나 주파수 영역에서는 위상 정보를 포함한 복합적인 파형 특성이 반영되어야 하므로 송신원 추정 과정이 더 복잡하다. 이러한 특성은 신경망의 학습 안정성과 성능에 영향을 미칠 것으로 예상된다.
현장 자료 적용 가능성
본 연구에서 라플라스 영역에서의 송신원 추정을 통해, 서로 다른 파형을 가진 관측 자료를 훈련 자료의 파형과 잘 일치하도록 성공적으로 디컨벌루션을 수행할 수 있었다. 따라서, 제안된 방법이 다양한 송신 파형을 가진 현장 자료에도 적용할 수 있음을 충분히 예상할 수 있다. 그러나, 본 연구에서 훈련된 신경망을 실제 현장 자료에 적용하기 위해서는 아직 해결해야 할 부분들이 남아 있다. 비록 두 벤치마크 모델을 포함한 2차원 현장 규모 크기의 합성 속도 모델 예제에서는 충분한 역산 성능을 보여주었지만, 현장 자료에 적용하기 위해서는 잡음에 대한 연구가 필요하다. 이를 위해, 후속 연구에서는 훈련 데이터에 잡음을 포함시켜 신경망의 견고성을 향상시키거나, 라플라스 영역으로 변환된 현장 자료 내 잡음을 제거하는 접근법을 고려할 수 있다.
본 연구에서는 고정된 송수신기 배열 및 일정한 크기의 속도 모델을 기반으로 지도학습을 수행하였다. 학습에 사용된 설정이 아닌 다른 송수신기 배열 정보나 크기가 상이한 속도 모델의 경우, 보간을 수행하거나 해당 조건에 맞게 신경망을 다시 훈련해야 된다. 또한, 불균일한 밀도, 이방성, 훈련 자료 생성에 사용한 파동 방정식 등 다양한 요인들이 신경망의 일반화 성능에 영향을 미친다. 이러한 다양한 경우를 모두 고려하여 일반화 성능을 향상시키기 위해서는 방대한 양의 훈련 자료와 연산 자원이 요구된다. 그러나 본 연구에서 제안한 접근법은 훈련 비용이 높지 않으므로 이러한 조건이 바뀌었을 때 해당 조건에 맞는 훈련 자료를 새로 생성하여 신경망을 다시 학습시키는 것이 연산 효율면에서 더 바람직할 수 있다.
향후 연구 방향
본 연구는 딥러닝 기반 탄성파 역산에서 송신원 추정의 중요성에 초점을 맞춰 수행하였다. 이에 따라, 송신 파형의 영향을 가장 크게 받을 수 있는 지도학습 기반 탄성파 역산을 채택하였으며, 제안된 방법의 효과를 수치 실험을 통해 정량적으로 분석하였다. 본 연구에서 제안된 접근법은 전처리 과정이므로 지도학습에만 국한되지 않으며, 다른 딥러닝 기술을 활용한 탄성파 역산에도 적용 가능하다. 예를 들어, 전이 학습 기반 네트워크 매개변수화(Jo and Ha, 2024)에 송신원 추정을 통합하는 방식도 고려할 수 있다. 이 경우, 지도학습 단계가 아닌 네트워크 매개변수화 과정에 송신원 추정을 포함함으로써 보다 정확한 속도 모델을 도출할 수 있다.
본 연구에서 제안된 접근법의 경우 속도 매개변수와 송신원 매개변수를 따로 추정하므로 분리적 접근이라고 할 수 있으며, 이 두 매개변수를 동시에 추정하는 방법은 동시 최적화라고 표현할 수 있다. 향후 연구에서는 라플라스 영역 딥러닝 기반 탄성파 역산에서 분리적 접근과 동시 최적화 전략을 비교하여 각각의 성능을 평가할 예정이며, 추가적으로 잡음의 영향을 고려한 실험도 함께 수행함으로써 최종적으로 현장 자료에 적용하는 것을 목표로 한다.
결 론
지도 학습 기반 탄성파 역산은 정확한 초기 속도 모델의 필요성을 제거하며, 훈련이 완료된 후의 예측 비용은 무시할 수 있다. 특히, 라플라스 영역 지도학습 기반 딥러닝 탄성파 역산은 제한된 계산 자원 내에서도 현장 규모의 자료에 적용 가능하다는 장점이 있다. 다만, 입력으로 사용되는 라플라스 영역 파동장은 감쇠에 따른 정보 손실로 인해 역산 결과의 해상도가 상대적으로 낮아지는 한계를 지닌다. 그럼에도 불구하고, 해저 지층을 시뮬레이션한 합성 속도 모델 예제에서 훈련된 신경망이 우수한 예측 성능을 보여주었으며, 신경망 구조를 적절히 설계할 경우 역산 성능을 더욱 향상시킬 수 있음을 입증하였다. 정확한 송신원 매개변수의 추정은 현장 자료에 대한 성공적인 역산을 위해 매우 중요하다. 본 연구에서 송신원 추정 알고리즘은 기존 전파형 역산에서 사용하는 것과 동일하며, 뉴턴법을 이용해 송신원 매개변수를 반복적으로 추정하였다. Marmousi 및 Pluto 벤치마크 속도 모델을 이용한 수치 예제를 통해 딥러닝 기반 탄성파 역산에서의 송신원 추정의 중요성을 검증하였고, 제안된 접근법이 다양한 송신 파형에 대한 추가적인 지도학습 없이도 적용 가능함을 확인하였다. 향후 연구에서는 라플라스 영역 딥러닝 기반 탄성파 역산에서 송신원 추정뿐 아니라 잡음의 영향을 함께 고려함으로써 현장 자료에 적용하는 것을 목표로 한다.
